
Continuing on from our previous posts about Databricks, we are now going to look at structured streaming. For this blog post we are going to use some data from the Seattle fire service that is updated every 5 minutes.
The source data we are going to use can be found at https://data.seattle.gov/Public-Safety/Seattle-Real-Time-Fire-911-Calls/upug-ckch
- Navigate to the link above and familiarise yourself with the type of data that we will be using
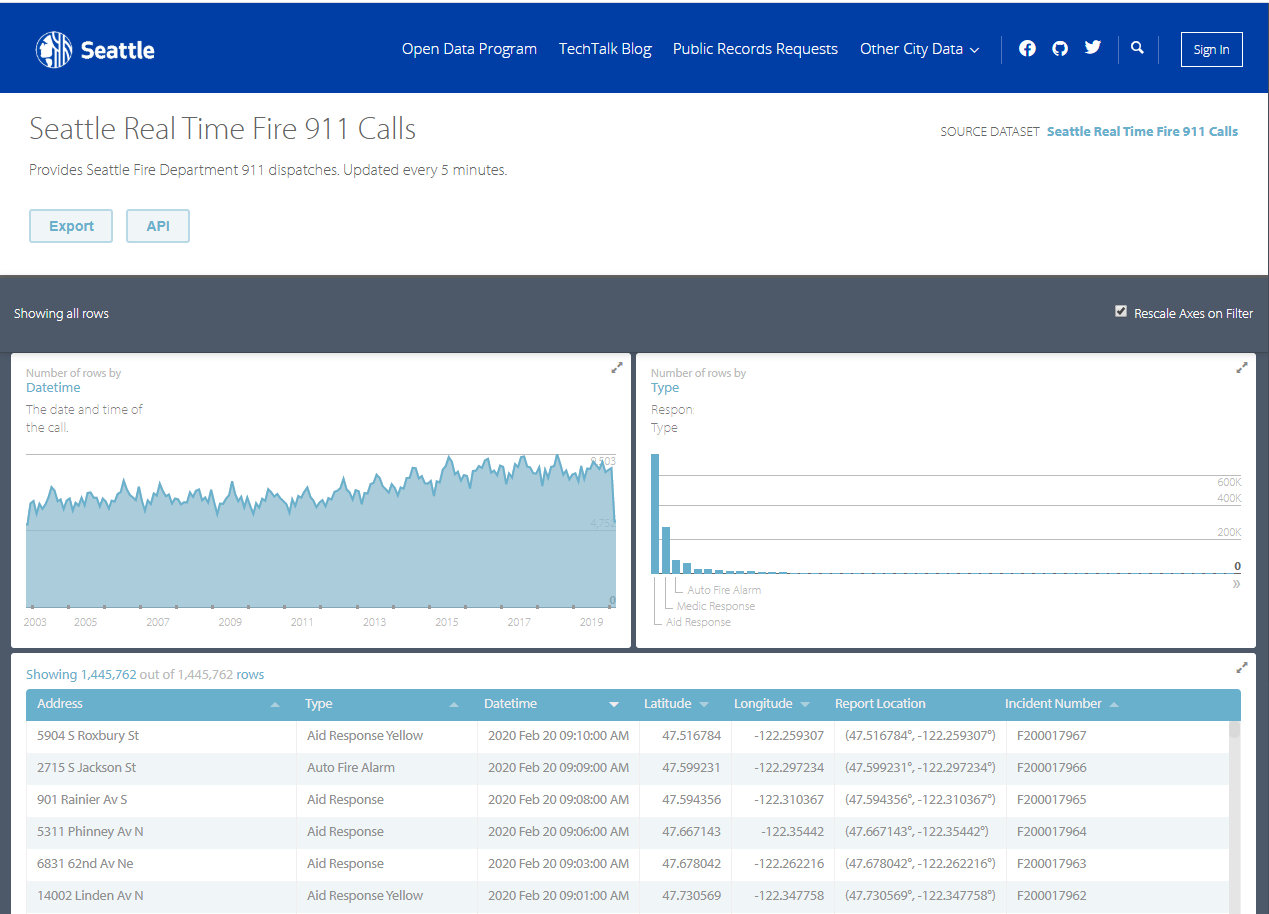
- Click on the SOURCE DATASET "Seattle Real Time Fire 911 Calls" to display information about the dataset

- Navigate back to the previous page and click on the "API" link
- Make a note of the URL in the link (copy to the clipboard)
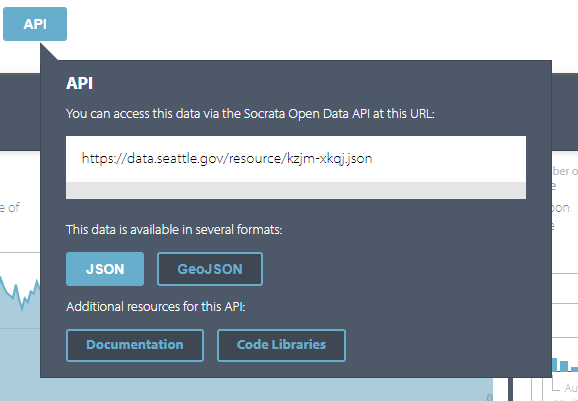
- In a new browser window paste in the URL to view the content from the API
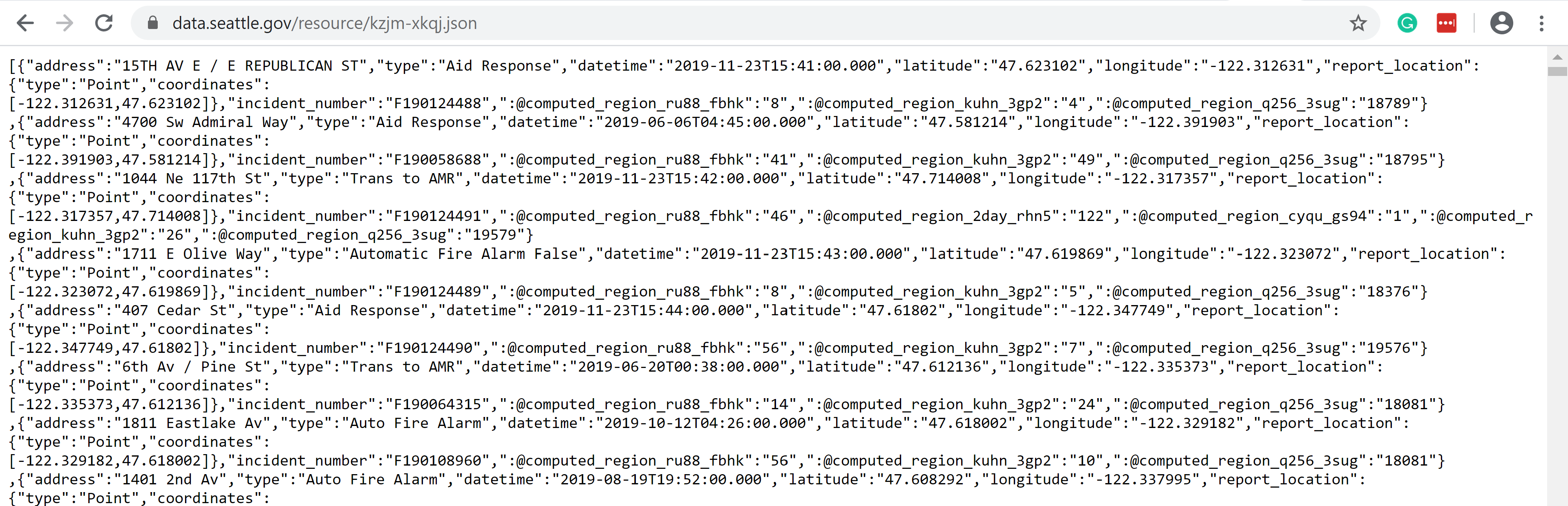
- Using the Databricks cluster created in the previous post
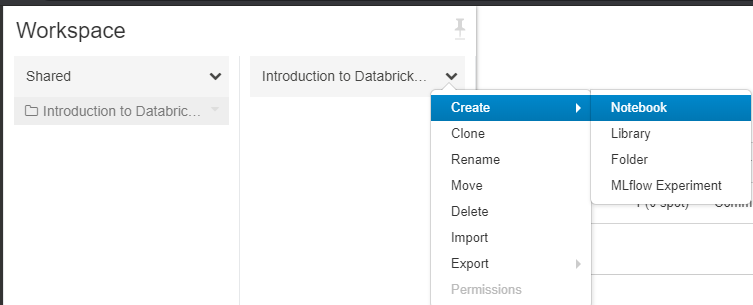
- Navigate to "Workspace"
- Navigate to "Shared" > "Create" > "Folder"
- Enter the name "Introduction to Databricks Structured Streaming" and click "Create Folder"
- Navigate to the folder and click "Create" > "Notebook"
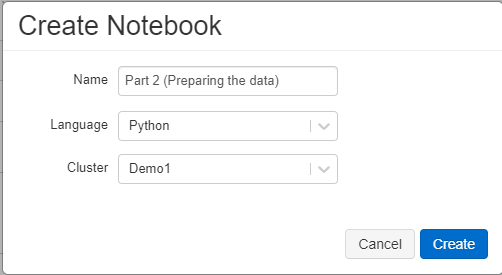
- Create a Python notebook called "Part 2 (Preparing the data)"
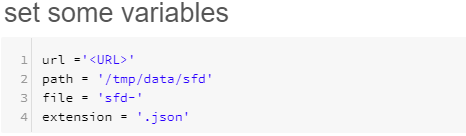
- Enter the following code into the cmd pane of the notebook. These are the variables that we will use for getting the data from the website and saving it to a file.
- Get the URL for the data stream and paste it where <URL> is above, this can be found from the API button on the following web page
https://data.seattle.gov/Public-Safety/Seattle-Real-Time-Fire-911-Calls/upug-ckch
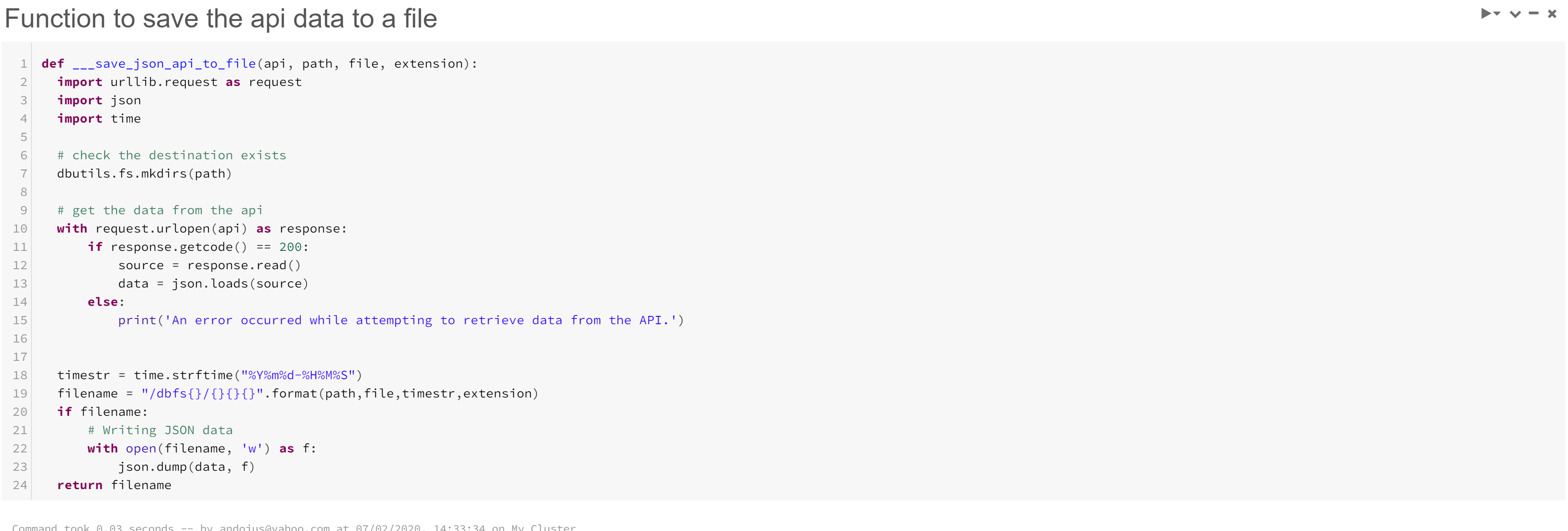
- Add another cmd pane by clicking on the + that appears below the middle of the previous one and add the following code. This provides a function that we will use save the stream to a file
- Add another cmd pane and add the following code to test that the data is captured to a file
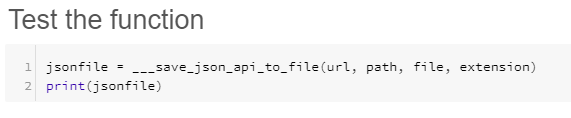
- To test the code you can either click the
 at the top of the notebook or run each cell individually using the play button in the top right. "Test the function" should return something similar to the following
at the top of the notebook or run each cell individually using the play button in the top right. "Test the function" should return something similar to the following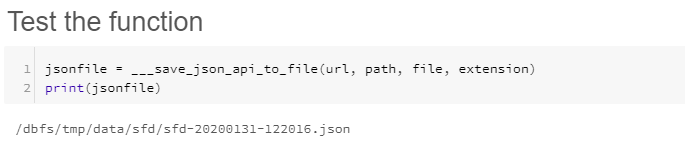
- To check that we have some files you can run the above a few times, but leave 5 minutes between executions to allow the source data to refresh.
- Enter the following in another cmd pane to check that we have some files to process
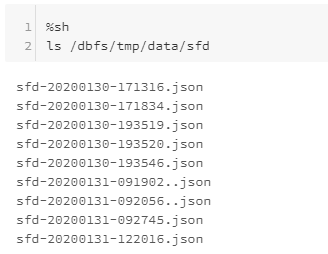
We now have some data that we can use to test structured streaming.
In this post we have:
- Created function to pull data from an external API
- Created Json files that we can use as the source for our structured streaming dataset.
In the next post we will connect to the json files using structured streaming.
