
Welcome to this series of blog posts on Azure Databricks, where we will look at how to get productive with this technology. In Part 1, as with any good series, we will start with a gentle introduction.

What is Azure Databricks?
Apache Spark
Before we talk about Databricks we need to first mention Apache Spark as it is this product that provides the core functionality. Apache Spark is a cluster computing framework, which probably sounds quite daunting, but we can think of it as just doing a lot of the heavy lifting when scaling workload processing.
A workload's processing speed is determined by the resources available. If the process is run on a single resource processor then we vertically scale up by making that resource larger or faster and therefore decreasing the time taken to complete our task. Another way that scaling can be implemented is using horizontal scale and this is achieved by adding more workload processors.
In the diagram below data to be processed is represented by a bag and the processor with an actor icon:
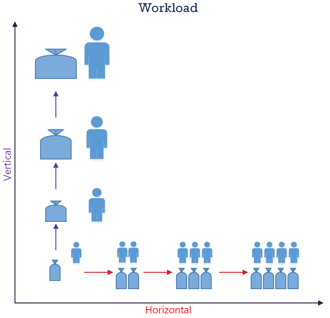
Vertical scaling is the easiest technically because bigger or faster resource doesn't require any difficult problem solving. Horizontal scaling, however, requires that we split our workload into chunks and divide those pieces into multiple work streams. These work streams require co-ordination to process and to create a combined output. Plus, we need to make sure that these are resilient to failure. There are lot of things to think about, but thankfully this is taken care for us by Apache Spark.
Databricks
Databricks is Apache Spark and some secret sauce. The original creators of Apache Spark created Databricks to make it easier to be more productive with Spark. They added a collaborative web-based interface and the ability to integrate quickly with other services as well as lots of other things. A comparison between Apache Spark and Databricks can be found at https://databricks.com/spark/comparing-databricks-to-apache-spark.
Azure Databricks
Azure is a cloud computing service created by Microsoft to provide not only infrastructure, but also a huge number of other services developed by Microsoft as well as other 3rd parties. Azure Databricks is an optimized deployment of Databricks developed for the Microsoft Cloud. It provides further enhancement such as authentication integration directly with other Azure services.
What is Azure Databricks to me?
In summary, Azure Databricks is Apache Spark at the core with enhancements and optimisation. Azure Databricks is a platform that can be used to Extract, Transform and Load (ETL) data. For those of you not familiar with ETL, this is the process of taking some data from one source to another and performing some action upon it. A simple example might be a list of sales from multiple sites, that are loaded, combined and then exported as total sales across all sites.
Now for those with some familiarity with Azure Databricks I can picture you shouting at the screen at this point telling me that it is so much more than an ETL tool. The Databricks website states it provides a Unified Analytics Platform that "unifies data science and engineering across the Machine Learning lifecycle from data preparation, to experimentation and deployment of ML applications". For now just bear in mind that it can do all the traditional ETL, plus lots of very cool analytics using artificial intelligence (AI).
Ready to do more with Databricks? Read Part 2 of this series where we go into more detail around deployment.
