
Updated May 2021
I keep hearing this question being asked. It's not well documented nor is it widely known, but we know it's associated with the way failover clustering interacts with the Azure networking infrastructure. My latest blog post attempts to unravel this mystery and explain why the behaviour is different between on-premises and Azure.
It all starts with understanding some basic networking principles. On-premises Windows Server Failover Clusters (WSFCs) work on the basis that when a failover occurs between a primary and a secondary node, a gratuitous Address Resolution Protocol (GARP) is broadcast on the network. Fundamentally, the Address Resolution Protocol (ARP) is a request-response protocol used to resolve MAC addresses at the TCP/IP Link Layer (known as Layer 2) with an IP address at the TCP/IP Internet Layer (known as Layer 3). GARP requests are useful when we need to update MAC-to-IP mappings (aka. ARP tables) within routers and switches that are attached to the network, whereas a GARP reply is a type of response for which no request may have occurred - in other words, it's gratuitous. Within a WSFC, when an Availability Group Listener fails over, a GARP is broadcast to map the MAC address of the new primary replica with the IP address of the Availability Group Listener. This binds the Listener IP address with the NIC of the new primary replica; ensuring that new Listener connections are routed correctly.
By performing a network-level trace using a tool like Wireshark, we can see this in action with an on-premises Availability Group. Let's look at a quick example.
In our test lab (thanks to Jon Gurgul for lending me his setup), there is an Availability Group with two replicas: VWH11 and VWH12 (both on-premises). The Availability Group Listener, called "AGL" has an IP address of 10.20.1.69, which can float between the two replicas. VWH11 has an IP address of 10.20.1.11 and a MAC address of 00-15-5D-73-51-3F, whilst VWH12 has an IP address of 10.20.1.12 and a MAC address of 00-15-5D-73-51-45. It's important to note that VWH11 is the current primary replica. The diagram below provides a visual representation of this setup.

From reading this article, we can assert that; during failover the new primary replica should request and configure the Availability Group Listener IP address on its Network Interface Card (NIC). To test this theory, a Netmon trace was setup on VWH11 and VWH12 to capture packets being sent as VWH12 became the new primary replica. By filtering the ARP requests within the trace before the failover, we can see the source MAC address 00-15-5D-73-51-3F (VWH11) is broadcasting its request for 10.20.1.69 (the Availability Group Listener).

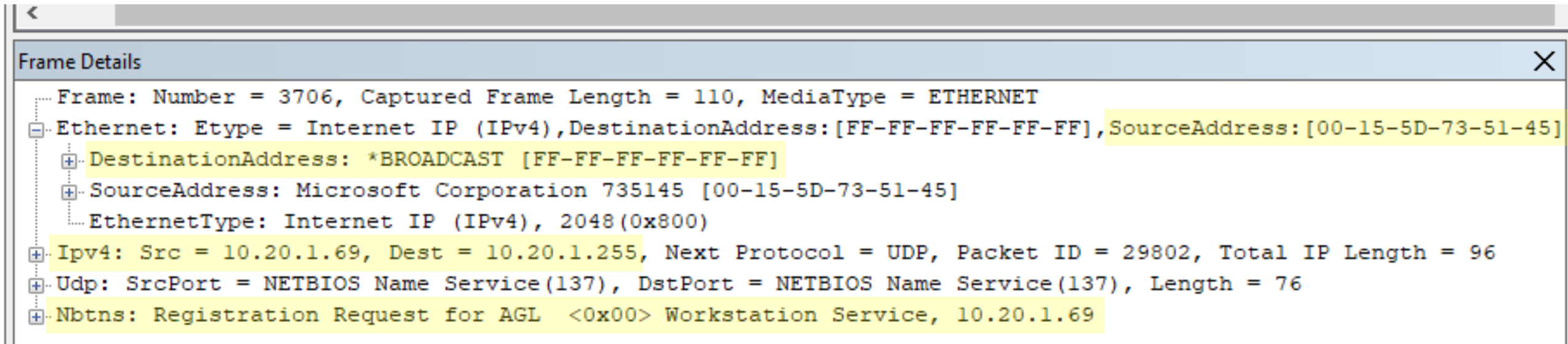
Notice the destination MAC address is FF-FF-FF-FF-FF-FF. This is known as the broadcast address (Layer 2), which all network attached devices use to update their ARP tables. In the screenshot below, the new primary replica VWH12 (00-15-5D-73-51-45) broadcasts a request for 10.20.1.69 after the failover. All devices receiving this request will update their ARP tables to map the physical address; 00-15-5D-73-51-45 with 10.20.1.69.

The broadcast address translates to a Layer 3 IP address on the network. Since the subnet has an address space of 10.20.1.0/24, that gives me a subnet mask of 255.255.255.0 and a broadcast address of 10.20.1.255 (click the link to see how this is calculated). By filtering the trace to all requests going to 10.20.1.255, we can see that VWH12 broadcasts a NETBIOS Name Service (NBTNS) registration request for "AGL", which shows that VWH12 is now the primary replica.
Wait, so how is it different in Microsoft Azure?
Microsoft states that broadcasts are blocked within Azure Virtual Networks (VNETS) and are therefore not supported. It's important to note that Microsoft aren't the only cloud provider to do this; Amazon Web Services (AWS) doesn't support broadcasts within Virtual Private Cloud (VPC) networks nor does Google Cloud allow them within its VPC equivalent. Cloud providers do this to mitigate the risk of multicasting and broadcasting storms, which present a security risk and could impact network performance.
To work around this behaviour in Azure, Microsoft states that an Internal Load Balancer (ILB) is needed, should the application connect to an Availability Group Listener for high availability. Fundamentally, the ILB is associated with a VNET and has a frontend IP address within the chosen subnet range. This IP address serves as the entry point for application connections (i.e. applications connecting to the Availability Group Listener). There is also a Backend Pool that associates the virtual machines with the ILB, allowing traffic to flow from the frontend IP address to these virtual machines. To determine which virtual machine is the primary replica, the ILB probes each virtual machine on a user-defined port (e.g. 59999), allowing the ILB to route subsequent connections to the one that responds.
By running the command "netstat -ano" on the primary replica, you will notice that the ILB probe port is bound to a process called RHS.exe. Without going into too much detail, the Resource Hosting Subsystem (RHS) process loads cluster resource DLLs, in isolation from everything else. This was introduced in Windows Server 2008 R2 to prevent resource crashes affecting the availability of other resources within the same RHS process. You can read more about this here. Interestingly, if you run the same command on the secondary replica, RHS.exe is not bound to the ILB probe port. We can safely say therefore that this process helps the ILB identify which clustered node is the primary replica.
There are always going to be subtle differences between the way we deploy resources on-premises and in the cloud. In this scenario, cloud providers deliberately prevent broadcasts to improve network security and maintain performance for all their cloud customers. Load balancers provide a logical alternative which makes sense, once you get your head around them! That's all for now, I hope you found this one useful!
