
In this blog post I will talk about a very common issue in SQL Server: deadlocks.

If you get the above error 1025 it means that your process encountered a deadlock and was chosen as the deadlock victim and terminated. A deadlock occurs when two or more transactions hold mutually incompatible locks and cannot proceed without SQL Server intervening.
Generally speaking, the most common deadlocks occur when two (or more) sessions that hold an exclusive lock are unable to place another lock because the resource is already locked by the other competing transaction.
Let’s assume the below two sessions ran at the same time:
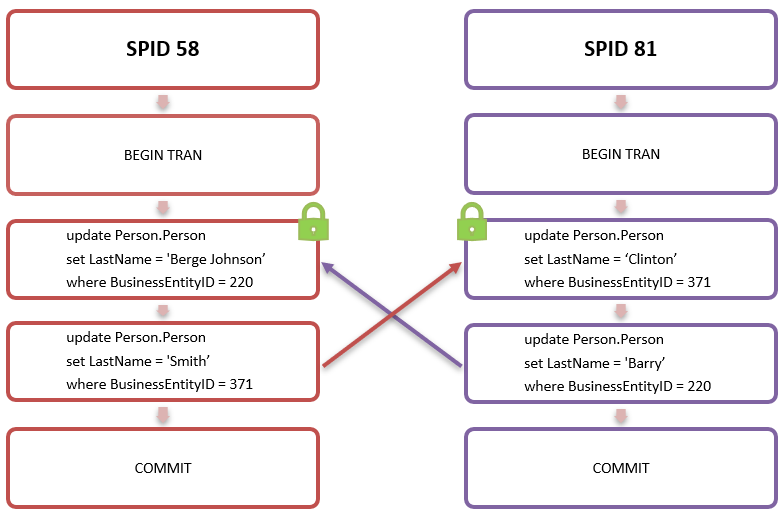
SPID 58 updated the ‘LastName’ column in the ‘Person.Person’ table for row with ‘BusinessEntityID’ (ID) 220 and concurrently SPID 81 ran the same update statement for the row with ID 371. The two sessions held an exclusive lock on rows with ID 220 and 371 respectively but they had not yet committed. SPID 58 then tried to update row with ID 371, which was locked by SPID 81, and SPID 81 tried to update row with ID 220, which in turn was locked by SPID 58: neither sessions could proceed.
Let’s have a look at the deadlock graph:
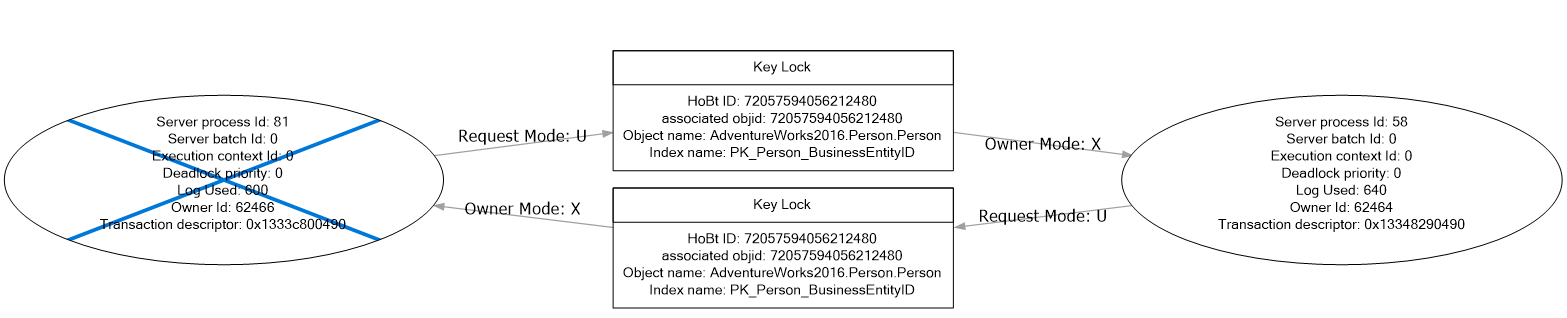
As you can see from the above graph, both SPIDs 81 and 58 owned an exclusive key lock, then they requested an update lock for a row that was already being locked by the other SPID. At this point neither session could proceed and SQL Server decided to kill SPID 81, rolling back the work so far. SPID 56 completed successfully.
The database engine checks for this type of situation approximately every 5 seconds (depending on deadlocks frequency) using a system process called ‘LOCK_MONITOR’ and terminates (kills) the transaction, known as the deadlock victim, that has done the least amount of work or is the least expensive to rollback. This breaks the deadlock and allow other transactions to proceed and resume their work.
The only exception to the above statement is if the deadlock priority has been changed at the session level. By default, the deadlock priority is set to 0 meaning that the database engine decides which transaction should be killed. If you set the deadlock priority to a different value, SQL Server kills the transaction with the lowest deadlock priority.
| Deadlock Priority | Value |
| LOW | -5 |
| NORMAL (default) | 0 |
| HIGH | 5 |
| NUMERIC VALUE (range) | -10 to 10 |
|
1
2
3
4
5
6
7
8
9
10
11
12
|
--Check your session's deadlock prioritySELECT deadlock_priorityFROM SYS.dm_exec_sessionsWHERE session_id = @@SPID--Change deadlock priority to HIGHSET DEADLOCK_PRIORITY HIGHGO--Change deadlock priority to a numeric valueSET DEADLOCK_PRIORITY -10GO |
This is very simple example just to get the concept right, but there are other types of deadlocks and they sometimes become very complicated with several sessions involved. Other common types of deadlocks are conversion and key lookup deadlocks.
As the name suggests, conversion deadlocks occur when a transaction tries to convert an acquired lock to another exclusive lock, or tries to acquire two locks separately and simultaneously, but it’s unable to do so because the resource is already locked by another transaction. You may see this type of deadlocks when intent locks are used: shared with intent exclusive (SIX), shared intent update (SIU) and update intent exclusive (UIX).
Key lookup deadlocks are very interesting because they can occur between two sessions that are running one single statement. I recently came across this type of deadlocks for a customer that had experienced hundreds! There was only one update statement involved from multiple sessions and the execution plan looked like the one below:
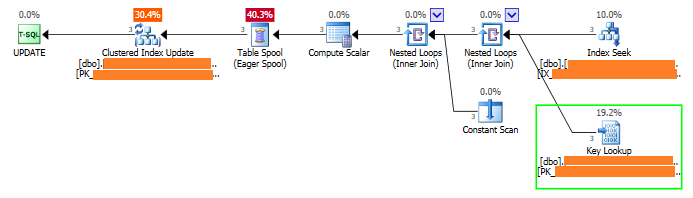
As you can see, SQL Server performed a seek on the non-clustered index, which was non-covering, and then a lookup on the clustered index to get the non-included columns. Because of the lookup, each session had to obtain two exclusive locks: one to update the rows in the clustered index and the other one to perform the key lookup. This situation can lead to a deadlock and in this case the customer experienced hundreds of them due to the high concurrency.
Deadlocks are not evil
Deadlocks are not to be confused with blocking, which is when a session (A) requests a lock on a resource that is already locked by another session (B). In this case session A will wait until session B completes and release the lock. Blocking can be a critical issue and I’ve seen systems with blocking chains involving dozens of sessions for several hours.
Some people tend to panic when they see deadlocks. I have seen customers raising P1 issues, but found after investigation that they had a couple of deadlocks in a few hours for a stored procedure that was called thousands of times a minute.
As explained earlier in this blog, SQL Server internally handles and resolve deadlocks which would otherwise result in infinite blocking between two or more sessions.
If your database is highly transactional with thousands of concurrent batches/transactions per seconds, sporadic deadlocks are actually not bad and prevent issue like blocking chains, long-running queries and timeouts. This is, of course, assuming that your application handles errors with a robust retry logic!
Would you rather have two or more sessions waiting on each other forever or have some sporadic failures which can be quickly handled and re-tried at the application level? I’d say the latter but it’s your responsibility to make the right decision based on your needs. On the other hand, if you start seeing tens or hundreds of deadlocks, well then something isn’t right.
How to detect Deadlocks
There are several ways of detecting and capturing deadlocks including third party tools, SentryOne being my favourite. SQL Server provides several different ways of detecting and capturing deadlocks information. Here are some of them in order of preference, 1 being my least favourite:
1. Trace Flags
Enable trace flags 1204 and/or 1222 to print deadlocks information in the SQL Server error log:
|
1
2
3
4
5
6
7
8
9
|
--#Enable Trace Flags GloballyDBCC TRACEON(1204,1222,-1)GO--#Check Trace Flags StatusDBCC TRACESTATUS(1204,1222,-1)GO--#Disable Trace Flags GloballyDBCC TRACEOFF(1204,1222,-1)GO |
The above commands enable the trace flags globally until next restart - just beware you remember you add the flags as start-up parameters in the SQL Server configuration manager if you want the change to be persistent in case of a SQL Server restart:
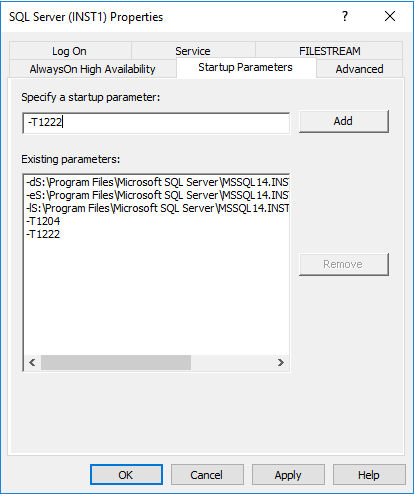
I wouldn’t personally recommend using this method as it can easily make your SQL Server error log look very ugly and extremely difficult to read when it comes to investigate other issues. With both trace flags enabled, I counted 57 rows in the SQL Server error log for that simple deadlock. Imagine how big and difficult to read your error log would become if you have dozens or hundreds of deadlocks. Not ideal.
2. SQL Server Profiler
You could run a profiler trace to capture deadlocks events. SQL Server Profiler was deprecated and may be removed in a future version of SQL Server, however, it is still available in SQL Server 2019. It is a very robust tool for troubleshooting SQL Server performance issues and I still personally use it if I need to run a quick trace on a system. It is also very easy to use.
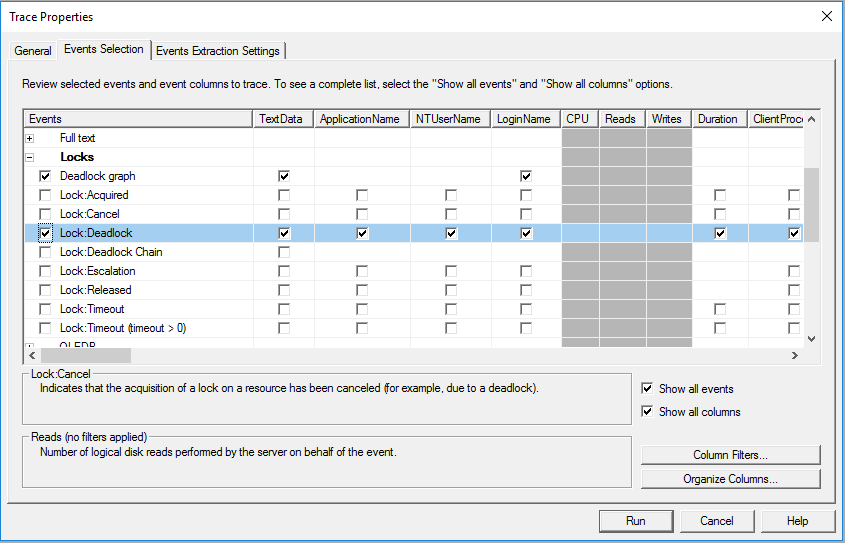
From the event selection tab of a new SQL Server Profiler trace, select the ‘Deadlock:Graph’ and ‘Lock:Deadlock’ events under the ‘Locks’ category:
3. Extended Events
Extended events (XE) are by far my favourite and surely the most common and efficient method for capturing deadlocks.
The ‘system health’ extended event, which is created and enabled by default, contains some general SQL Server health events and also captures deadlocks. However, a deadlock may not necessarily be captured by the ‘system health’ XE as extended events allow single event loss by default and as per best practice.
This means that an extended event can disregard and miss single events. Deadlocks graphs can be quite large (even a few MBs) and if SQL Server needs to choose between tracking several events or a single 3MB deadlock graph, it may disregard the deadlock and chose to log the other events.
If you have a major deadlock issue that is affecting your system and you need to capture every single occurrence without exclusions, you should create a dedicated extended event for deadlocks and disallow event loss, although it is NOT recommended under usual circumstances.
Create a new XE for deadlocks with NO event loss
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
IF EXISTS(SELECT * FROM sys.server_event_sessions WHERE name='Deadlock_XE') DROP EVENT session Deadlock_XE ON SERVER; GO CREATE EVENT SESSION [Deadlock_XE]ON SERVER ADD EVENT sqlserver.xml_deadlock_report ADD TARGET package0.event_file (SET filename=N'Deadlock_XE',max_rollover_files=(10)), ADD TARGET package0.ring_buffer WITH (STARTUP_STATE=ON,EVENT_RETENTION_MODE=NO_EVENT_LOSS,MAX_MEMORY=4MB,MAX_EVENT_SIZE=4MB)GOALTER EVENT SESSION [Deadlock_XE] ON SERVER STATE = STARTGO--CleanupDROP EVENT SESSION [Deadlock_XE] ON SERVERGO |
Query deadlock XE
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
|
--1. Find Deadlocks Extended Events and get the path of the target file (File Path)SELECT CAST(target_data as xml)FROM sys.dm_xe_session_targets xetINNER JOIN sys.dm_xe_sessions xes ON xes.address = xet.event_session_addressINNER JOIN sys.dm_xe_session_events xee ON xes.address = xee.event_session_addressWHERE xee.event_name = 'xml_deadlock_report' AND xet.target_name = 'event_file';--2. Query Extended Events Deadlocks ReportsDECLARE @StartTime datetime = '2019-04-16 00:00:00.003', @EndTime datetime = '2019-04-16 23:59:59.997'select @StartTime, @EndTime;with deadlocksas( SELECT CAST(DATEADD(mi,DATEDIFF(mi, GETUTCDATE(), CURRENT_TIMESTAMP),xevents.event_data.value('(event/@timestamp)[1]','datetime2')) AS datetime) AS [Event Time] ,CAST(xet.event_data as xml) AS [Deadlock Report] from sys.fn_xe_file_target_read_file ('[target files path]\*.xel' --Replace with file path you get from query 1 ,'[target files path]\*.xem', null, null) xet --Replace with file path you get from query 1 cross apply (select cast(event_data as XML) as event_data) as Xevents where object_name = 'xml_deadlock_report')SELECT [Event Time] ,[Deadlock Report]FROM deadlocksWHERE [Event Time]>= @StartTime and [Event Time] < @EndTime;--3. Query Extended Events Deadlocks detailsDECLARE @StartTime datetime = '2019-04-16 00:00:00.003', @EndTime datetime = '2019-04-16 23:59:59.997'select cast(getdate() as datetime2)CREATE TABLE #Deadlocks ( DeadlockID int identity(1,1), Event_Data XML, EventTime datetime );with deadlocksas( SELECT CAST(DATEADD(mi,DATEDIFF(mi, GETUTCDATE(), CURRENT_TIMESTAMP),xevents.event_data.value('(event/@timestamp)[1]','datetime2')) AS datetime) AS [Event Time] ,CAST(xet.event_data as xml) AS [Deadlock Report] from sys.fn_xe_file_target_read_file ('[target files path]\*.xel' --Replace with file path you get from query 1 ,'[target files path]\*.xem', null, null) xet --Replace with file path you get from query 1 cross apply (select cast(event_data as XML) as event_data) as Xevents where object_name = 'xml_deadlock_report')INSERT INTO #DeadlocksSELECT [Deadlock Report] ,[Event Time]FROM deadlocksWHERE [Event Time]>= @StartTime and [Event Time] < @EndTime;WITH Deadlocks_CTEAS( select DeadlockID ,event_data ,EventTime --,event_data.value('(//process-list/process/@id)[1]','varchar(200)') --,event_data.value('(//process-list/process/@waitresource)[1]','varchar(200)') ,Deadlock.Process.value('@waitresource', 'varchar(100)') AS WaitType ,Deadlock.Process.value('@waittime', 'int') AS WaitTime ,Deadlock.Process.value('@spid', 'int') AS SPID ,Deadlock.Process.value('@ownerId','int') AS OwnerID ,Deadlock.Process.value('@lockMode','varchar(10)') AS LockMode ,Deadlock.Process.value('@priority','int') AS DeadlockPriority ,Deadlock.Process.value('@trancount','int') AS TranCount ,Deadlock.Process.value('@lastbatchstarted','datetime') AS LastBatchStarted ,Deadlock.Process.value('@lastbatchcompleted','datetime') AS LastBatchCompleted ,Deadlock.Process.value('@clientapp','varchar(200)') AS Application ,Deadlock.Process.value('@hostname','varchar(100)') AS HostName ,Deadlock.Process.value('@isolationlevel','varchar(100)') AS IsolationLevel ,Deadlock.Process.value('@xactid','int') AS TranID ,Deadlock.Process.value('@currentdbname','varchar(100)') AS DBName ,Deadlock.Process.value('@loginname','varchar(100)') AS LoginName ,Deadlock.Process.value('@id','varchar(100)') AS ProcessID ,input.Buffer.query('.') as InputBuffer ,victim.list.value('@id','varchar(100)') AS VictimID from #Deadlocks cross apply #Deadlocks.event_data.nodes('//process-list/process') AS Deadlock(Process) cross apply #Deadlocks.event_data.nodes('//deadlock/victim-list/victimProcess') AS Victim(List) CROSS APPLY Deadlock.Process.nodes('executionStack') AS Execution(Frame) CROSS APPLY Deadlock.Process.nodes('inputbuf') AS Input(Buffer) CROSS APPLY (SELECT Deadlock.Process.value('@id', 'varchar(50)') ) AS Process (ID))SELECT DeadlockID ,EventTime as [Event Time] ,ProcessID ,CASE WHEN ProcessID = VictimID THEN 1 ELSE 0 END AS [Is Victim] ,SPID ,CASE Application WHEN '' THEN 'N/A' ELSE Application END AS [App Name] ,CASE HostName WHEN '' THEN 'N/A' ELSE HostName END AS [Host Name] ,LoginName ,DBName as [Database Name] --,table ,WaitType as [Wait Type] ,LockMode ,WaitTime as [Wait Time(ms)] ,TranCount ,IsolationLevel ,DeadlockPriority ,InputBuffer as [SQL Command] ,event_data as [Deadlock Graph]FROM Deadlocks_CTE--Cleanup--DROP TABLE #Deadlocks |
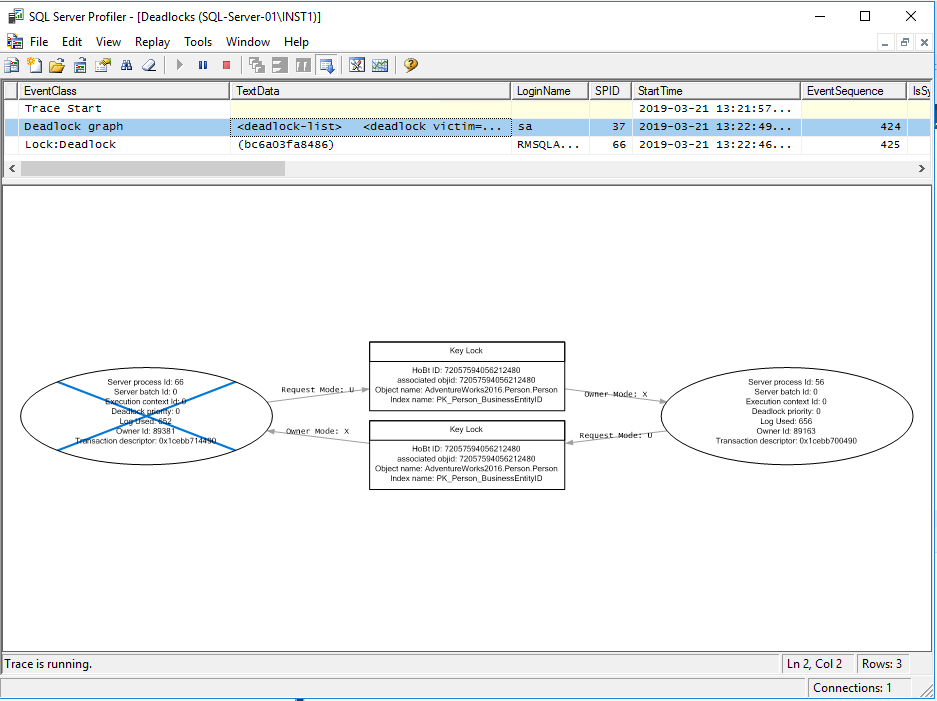
To view deadlocks' Extended Events in SSMS browse to Management, Extended Events, Sessions, expand you deadlock extended event session and right click on the event file to view target data. It will look like the screenshot below:
How to resolve deadlocks
Reduce likelihood may be very difficult, if not impossible in same cases. However, there are some ways to mitigate against them and reduce the number of occurrences:
- Make sure you write queries in a consistent way and tables rows are modified in the same order
- Avoid overlapping – i.e. avoid running big data loads, ETL processes and/or index maintenance at the same time if possible
- Investigate queries involved and check locks/lock escalations. You may find that your query resulted in a lock escalation (i.e. from a nice row/key lock to page, extent or even table lock) and is locking more data than it actually needs to
- Create supporting indexes to make your query is as efficient as possible and prevent large scans, unnecessary locks/lookups and lock escalations
- Run large DML statements in batches to prevent large scans and lock escalations
- Set the deadlock priority – if you know that a process is more critical than others and MUST complete, you can set the deadlock priority to HIGH or a to a value greater than 0 (default)
Summary
Deadlocks occurs when two (or more) sessions cannot proceed because they hold mutually incompatible locks on the same resources. SQL Server handles deadlocks internally and resolve them by killing the transaction with the least deadlock priority or the one that has done the least amount of work. Write queries sensibly and use the right indexes to minimise unnecessary locks.
We resolved the lookup deadlock issue mentioned above in this blog by creating a covering non-clustered index, which eliminated the need of a key lookup and the extra exclusive lock.
Roberto is a Data Platform Engineer working on Coeo's Dedicated Support team.
