
Anyone that's worked with SQL for any length of time will undoubtedly have seen and heard the following
"Yeah, we put nolock on the end of everything, it makes our queries much faster"
Now, if you're anything like me, that makes me shudder just a little bit. I don't have an issue with using nolock in theory, as long as you know what it actually does and you understand the risks involved in its use. Unfortunately, I'd all but guarantee that a good 80% of people using nolock don't understand the implications of what they are doing.
So the first thing to say is that with (nolock), is the equivalent of setting the database isolation level to "read uncommitted".
Even if you don't fully know what "read uncommitted" is, I think you'd agree that it sounds a fair bit more serious than "no lock".
Read Uncommitted
Read Uncommitted means exactly that, it allows you to read data from other transactions that haven't been committed to the database yet.
So, lets say that person A starts a transaction and inserts some records into table X. Nothing done inside this transaction actually exists in the database until the whole transaction is committed (at a very basic level, thats what transactions do).
During this same time, person B queries table X using a with (nolock), because that puts the query into read uncommitted isolation, person B gets to see all the data in table X plus the data that is still in flight (i.e. not actually committed to the database yet) from person A's insert.
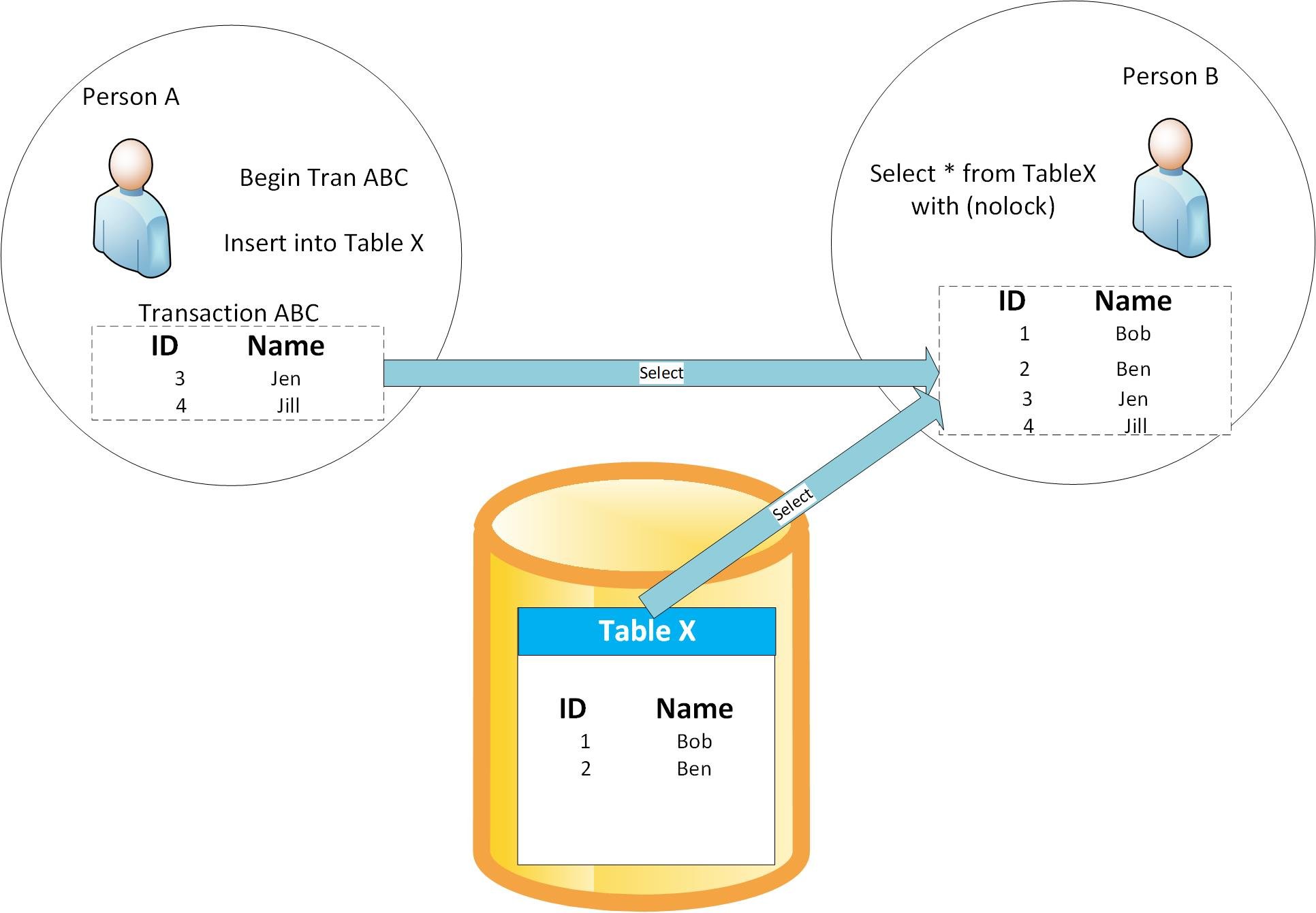
Fig1. Dirty Read
Person A then does a rollback, meaning the values they inserted get discarded and never make it into the database.
So, the data that person B has just got is incorrect, because his query returned data that never actually existed in the database. This is called a "dirty read".
Go Faster Stripes
The reason nolock (read uncommitted) "makes queries quicker" is mainly because of the lack of locks that queries in this isolation level take out on the target tables and its lack of observation of exclusive locks taken out by other transactions.
In a nutshell, nolock (read uncommitted) takes no shared locks to prevent other transactions from modifying data read by this transaction. It also effectively ignores exclusive locks taken by other transactions when they have added or changed data but not committed it yet.
So this does reduce contention in your database (different connections / people / apps trying to read from and write to the same table) and removes a large amount of the overhead of having to hold locks. This is why you'll see an increase in the speed of your queries.
Want to see something really scary?
What if I told you, you could run the exact same query twice, one after the other, in the same connection and get two different results? Sounds scary yet? :)
Lets say that for whatever reason, good or bad, the database is running in "Read Committed Snapshot" isolation level.
This isn't beyond the realms of plausibility, as its often used as a transition away from or alternative to, using nolock.
What "read committed snapshot" isolation level does is to use row versioning (which is a whole blog post in of itself), to give you the last committed version of the record as it looked when the statement started. This is a very simplistic explanation and I'd recommend having a look at row versioning in more detail.
Whilst RCSI does reduce contention in the database, it does come with some downsides of its own (which is outside the scope of this post, but there is a world of information on it with a quick google).
So lets walk this through, first we'll create a test database and set it to readcommitted snapshot
Use [master]
go
Create database Demo
go
ALTER DATABASE Demo
SET READ_COMMITTED_SNAPSHOT ON;
ALTER DATABASE Demo
SET ALLOW_SNAPSHOT_ISOLATION ON;
Now lets create a table and add some data to it
Use [Demo]
go
drop table if exists MyReallyImportantFinanceTable
go
Create table MyReallyImportantFinanceTable
(
ID int not null identity primary key
,FullName varchar(200) not null
,ReallyImportantFinancialValue numeric(10,2) not null
);
insert into MyReallyImportantFinanceTable (FullName, ReallyImportantFinancialValue)
values ('Bill', 10000.00),('Ben', 50000.50)
So we've now got our database, put it in read committed snapshot isolation and added a table with some data in it. Now we'll start a transaction and insert some new data
begin tran Ins
insert into MyReallyImportantFinanceTable (FullName, ReallyImportantFinancialValue)
values ('Jack',70000.50),('Jill', 100000.00)
So at this point we have two records "in flight", held in the transaction but not yet committed to the database.
Now go open another query window in management studio, this will create a second connection to the database and emulates a second user connecting. In this new window, we'll run exactly the same command, one with a nolock and one without
select sum(ReallyImportantFinancialValue)
from MyReallyImportantFinanceTable with (nolock)
select sum(ReallyImportantFinancialValue)
from MyReallyImportantFinanceTable
And, as promised at the top of this section, we've run the same command twice, one after the other and gotten two different results! If that doesn't bother you, I'm not sure what to tell you :)
Just as a tidy up, lets just rollback the transaction (and delete the database too if you want to)
rollback tran Ins
So, what happened there!?
Well, its quite simple really, the "Ins" transaction took out a lock on the table due to the insert. When we ran the queries in the second connection, the first select statement, which was the one with the nolock, ignored the lock taken out by the "Ins" transaction and read the table as is which included the two new records that were still in flight inside the "Ins" transaction
The second select statement didn't have the nolock, so it honoured the lock taken out by the "Ins" transaction and thus was redirected to the version store, because the database was in read committed snapshot isolation. SQL Server then used row versioning (as explained briefly above) to give you the last committed version of the rows, to avoid blocking.
And voila, we have the same statement giving two different results!
Wrap Up
So, hopefully you now understand what nolock does and will approach its use with a little more care, if not avoid using it all together.
If you have any questions or comments please feel free to post below and thanks for reading!