
Data no longer exclusively resides in on-premises data centres, with users gaining insight via a data extract from a relational database.
There is a data explosion across multi-cloud, on-premises and Software-as-a-Service applications. In addition, analytics is evolving from reactive processes to empowering users to make effective decisions based on data-driven predictions. When will a component fail? What will your customer purchase next, or will you pay back a loan?
Do you have aspirations to grow your business with predictive analytics? Machine learning involves using historical information to make predictions about the future. Here are three steps to get started:
- Envision
- Experiment
- Ethics

Envision
It’s essential to clarify your scope before starting:
- What is your use case?
- Who or what will call machine learning models, and what will they do with the results?
- What is your definition of success?
Machine learning expands into all areas of our lives. Do you want to predict a numeric value, such as journey time, fund value, insurance payout or profit? These projects are known as regression experiments.
Another type of machine learning is classification, where you want to predict from a discrete list. Examples are exam results (A, B, C etc.), sporting fixture results (win, draw, loss) or political affiliation. A subset of classification is a binary classification where you have two options, true or false. Will someone be affected by a disease, is a transaction fraudulent or is email spam?
Is machine learning integrated into your website or app, included in a Power BI dataset or maybe you will batch-predict based on spreadsheet data. Who are the consumers of your predictions, and are they customer-facing?
If you predicted correctly 100% of the time, there would be some poor bookmakers out there. What is your definition of success? Is it to be more accurate than a random guess, 75% accuracy or something else?
What data is at your disposal to test your experiments? Who owns the data, how will you authenticate and is the quality sufficient to support your needs? A mature data estate includes lineage and catalog tooling to clarify the data’s origins, journey and transformations.
A supervised machine learning experiment is one where the attribute you want to predict exists within the dataset. This attribute is known as the “Label”, which you use to verify your model’s accuracy before making predictions using new incoming data. “Features” are the attributes in your dataset you use to predict the Label.
You have clarified your project parameters, so now you can get started.
Experiment
Start by profiling your data of interest. For each attribute, establish the count of empty values and cardinality (uniqueness). Additionally, for numeric features, what is the min, max, mean and standard deviation. The goal here is to establish the features you will use to make predictions. Attributes with many empty values, very low or very high cardinality, are probably not good candidates.
I recommend getting started by using the Automated ML feature. Automated ML allows you to specify a dataset and configuration settings to create a machine learning experiment quickly. Microsoft provides a guided demo at https://docs.microsoft.com/en-us/azure/machine-learning/how-to-use-automated-ml-for-ml-models.
As you become more proficient with Azure ML, you can bypass the automated feature and create experiments using drag-and-drop graphical pipelines or code within notebooks. Some techniques provided by Azure ML you will use are:
- Normalisation – if you want to predict the outcome of a tennis match, you might have the following features; age of participants (range around 20 years), ranking (range hundreds), miles travelled to the tournament (range thousands). Normalisation is a machine learning technique to consistently scale numeric features, so the model doesn’t unfairly place greater significance on larger values.
- Transformation – select the columns you will use for predictions, remove duplicate rows, clean missing data and append datasets.
- Model Validation – Azure Machine Learning allows you to split data in your supervised experiments. This split means you train your model on a proportion of rows (say 70%) and keep 30% of your rows back to trial your model. As the experiment is supervised (containing known outcomes), Azure Machine Learning will compare your predictions against actuals.
- Model - Choose an algorithm such as Linear Regression or Two-Class Neural Network.
Don’t be intimidated by the algorithms or terminology if you are not familiar with those names. You can use the algorithms without a masters degree in mathematics or statistics. Your task is to interpret the results and try different combinations until you have reached your definition of success.
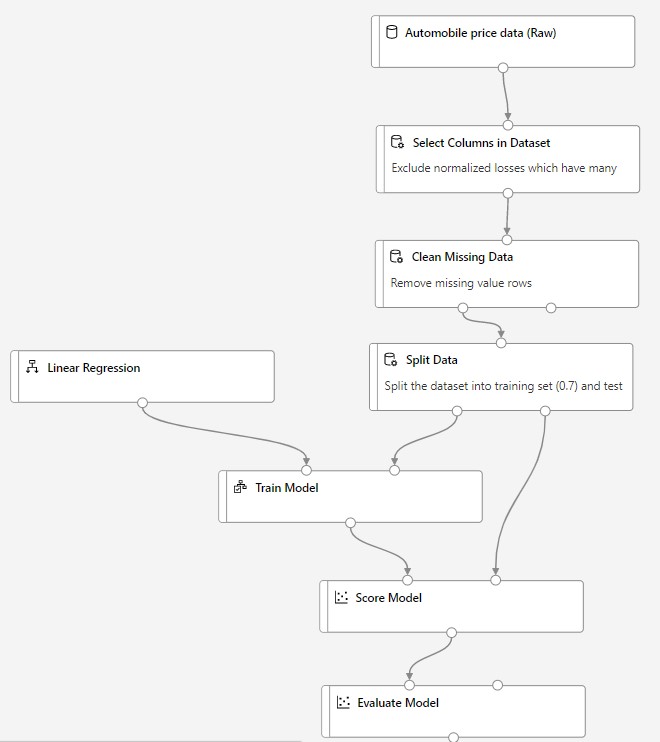
An example pipeline to predict the price of cars using the graphical drag-and-drop method:
Ethics
It is essential to bring an ethical approach to machine learning:
- How was your data source initially captured and are you using it for its intended purpose?
- What is the impact of incorrect predictions? This consequence ranges from serious if you’re predicting health outcomes to not so severe if it’s someone’s 10k running time.
- Who permitted the use of the data for this purpose?
- What bias did the data capture bring? Where there leading questions or limited survey options, for example?
- What bias do your models bring? Be conscious of amplifying societal bias within datasets and replicating the world as it is today.
- Do you bring an open mind or are you trying to prove your preconceived ideas?
Those are items for consideration. Also, ensure you implement security and compliance best practices following the zero-trust model.
Getting Started
Now you’re ready to get started with Azure Machine Learning. Navigate to https://aka.ms/azureml and experiment for free following the tutorials at https://docs.microsoft.com/en-us/azure/machine-learning/.
A great place to start is to use the Automated ML feature with a pilot project following the three Es above. Good luck!
