

We have all heard of locks and can probably even name a few; shared or exclusive locks, for example. We notice them more when something goes wrong and we run into blocking or other performance problems, but what are locks and how do they work in SQL Server?
In this blog, I aim to give a basic answer to that question and provide you with an overview of the different lock modes in SQL Server and how it all works…
Let us make it clear from the off; locks are an essential part of SQL Server. In a multi-user system, there will be many users who wish to access the same resources at the same time. This means that SQL Server must have measures in place to handle concurrency and prevent adverse side effects. Locking is one of those measures.
When the database engine processes a statement, the query processor decides which resources need to be accessed and how they will be used. Based on this information, it then determines what types of locks are required to protect each resource. The locks acquired also depend upon the transaction isolation level setting (more on that in a future blog). The query processor then requests the locks from the lock manager, which grants them if no conflicting locks are held by other transactions. If a conflicting lock is held by another transaction, the query will be made to wait until the other lock is released. In short, locks are there to protect resources.
Now that we know that locks are essential for the basic functioning of a healthy server, let us have a look at the different resources that can be locked. The following table shows the resources that SQL Server can place locks on:
|
Resource |
Description |
|
RID (Row Identifier) |
A single row within a heap |
|
Key |
A row lock within an index |
|
Page |
An 8Kb page in a database |
|
Extent |
A contiguous group of 8 pages |
|
HoBT |
A heap or B-tree |
|
Table |
The whole table including indexes |
|
File |
A lock on a database file |
|
Application |
A lock on an application-specific resource |
|
Metadata |
A lock on metadata |
|
Allocation_Unit |
A lock on an allocation unit |
|
Database |
A lock on the whole database |
|
Object |
A lock on anything that has an entry in sys.all_objects. E.g. a stored procedure or view |
SQL Server makes use of multigranular locking to try and minimize the cost of locking by allowing different types of resources to be locked by a transaction. Locking at a lower granularity, such as rows, increases concurrency, as access is only restricted to those rows rather than the whole table. Still, it has a higher overhead because a lock must be held on each row.
This overhead comes in the form of increased memory usage. A lock as an in-memory structure is 96 bytes in size, so locking millions of rows could have a high overhead compared to gaining a singular lock on the table.
SQL Server uses lock escalation to manage the locking granularity. Lock escalation is internally managed and decides at which point to move a set of locks to a higher granularity. This means that SQL Server dynamically manages locking without any input needed from the user.
The Database Engine typically acquires locks at multiple levels of granularity to fully protect a resource; this process is described as the lock hierarchy. Take, for example, a read of an index. To fully protect this read, SQL Server needs shared locks on rows and intent shared locks on the pages and table. If it did not do this, then something might gain a lock at a higher level, which would be problematic.
Lock Modes
Talking of the different lock modes, below is a quick summary:
|
Lock Mode |
Description |
|
Shared (S) |
Used for read operations that won’t need to update or modify data |
|
Update (U) |
Used for resources that might be updated |
|
Exclusive (X) |
Used for data modification operations |
|
Intent (I) |
Used to establish lock hierarchy (IS), (IX), (IU), (SIU), (UIX) and (SIX) |
|
Schema (Sch) |
Used when the schema of a table is updated |
|
Bulk Update (BU) |
Used to bulk copy data into a table |
|
Key-range |
Protects range of rows |
Shared locks allow concurrent transactions to read a resource, but no other transaction can modify the resource while the lock is held.
Update locks are used by transactions that might need to update the resource. Only one transaction can gain an update lock at a time. If data is to be modified, then the lock is converted to an exclusive lock. This means you can still acquire shared locks to read data while the update lock is held.
Exclusive locks are used to ensure that only one transaction can update data at one time and that nothing else can access that data unless the read uncommitted isolation level is set. (More on isolation levels in a coming blog).
Intent locks are used to protect the lock hierarchy and are acquired before locks are requested at lower levels. They protect the lower-level resources by stopping transactions modifying higher-level resources. They come in several different forms: Intent shared (IS), Intent exclusive (IX), shared with intent exclusive (SIX), intent update (IU), shared with intent update (SIU) and Update with intent exclusive (UIX).
Schema modification Locks (sch-M) are used to prevent concurrent access to a table while data definition/modification language operations, such as adding a column, truncating a table or dropping a table are happening.
Schema stability Locks (sch-S) are used when the database engine compiles and executes a query and only block sch-M locks.
Bulk Update Locks allow multiple threads to bulk load data concurrently into a table, while blocking access for processes that are not bulk loading data.
Key-Range Locks are used by the serializable isolation to protect against phantom reads by locking all value in a key range.
Lock Compatibility
An introduction to locking would not be complete without the lock compatibility table taken from Microsoft:
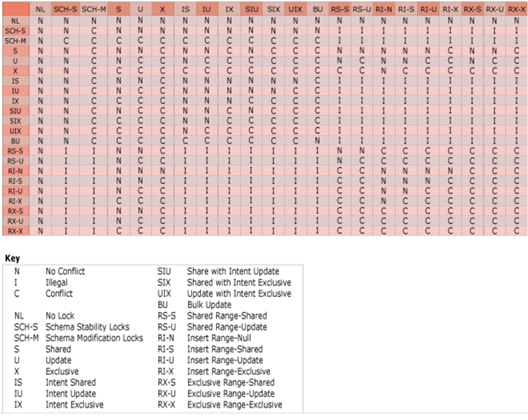
Lock compatibility controls whether concurrent transactions can acquire locks on the same resource at the same time. If a transaction requests a lock on an already locked resource, it will only be granted if it is compatible. If it is not, the transaction will have to wait for the lock to be released. This is an important point, because if a transaction spends a long time waiting for a lock, we can start to see problems. We might assume the process is running slowly, but in reality it is blocked as it can’t get a lock on the resource until the other transaction has released it.
Summary
This is only a fundamental overview, but how does it help you on a practical level? First, knowing the basics will help you have a better understanding of how different queries will interact and which operations will take locks that will block. This is a useful thing to have in mind when writing your code. Secondly, it is vital to know a bit about it, to make it easier to understand other concepts, particularly isolation levels, which I will come to discuss in a future blog.
It also allows you to do some basic troubleshooting if you see blocking taking place on your server and gives you an insight into why it might be happening. Hopefully, this blog has given you the basics to let you delve deeper into the internals of SQL Server.
Overall, we can see that locks are very useful, they ensure that multiple users cannot modify the same data at the same time. As a result of this it can occasionally appear that processes are running slowly, however it won’t be the process that is running slowly, it will be due to it spending time waiting on other processes to finish what they’re doing and release the locks. If this behaviour did not exist, you could quickly end up with inconsistent data in your database, which nobody wants!
There are a few good DMVs to investigate if you want to watch locking in action on your servers:
sys.dm_tran_locks (link)
The below image shows some useful columns in it, such as the status and the lock mode, as well as the resource type that the lock is targeted at.
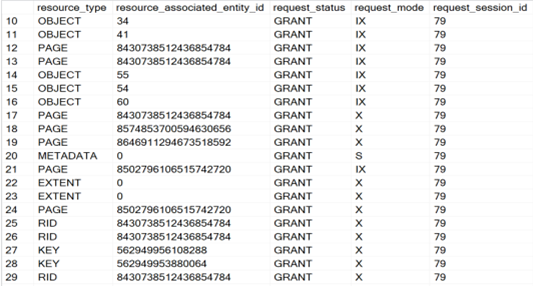
and joining it with sys.dm_os_wait_stats (link) can help you look into blocking on your server. More details and examples can be found in the links.
That is all for me in this blog, I hope you have found it useful and learned something, and I look forward to seeing you again on my next post!