The objective of any data warehouse should include:
- Identification of all possible data assets
- Select the assets that have actionable content and are accessible
- Model the assets into a high performance data
model - Expose the data assets most effective for decision making
New data assets are now available that may meet some of the above criteria but are difficult, or impossible, to manage using RDBMS technology. Examples of these are:
- Unstructured, semi-structured or machine structured data
- Evolving schemas, just in time schemas
- Links, Images, Genomes, Geo-Positions, Log Data
These data assets can be described as Big Data and this blog looks at Big Data stored in a Hadoop cluster.
In very few words Hadoop is an open source distributed storage and processing framework. There are a number of different software vendor implementations of Hadoop. The different Hadoop implementations should be investigated depending on your requirements.
Figure 1 highlights the key differences, and similarities, between relational database management systems (RDBMS) and Hadoop.
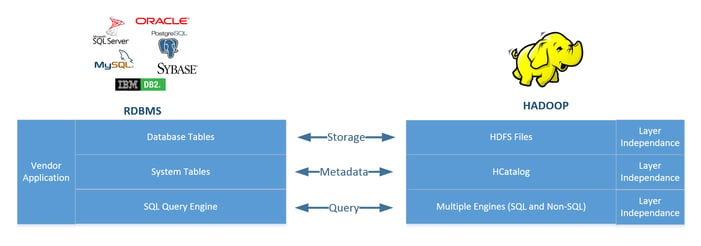
Figure 1 - Differences between RDBMS and Hadoop
The three layers that can be used to describe both systems are Storage, Metadata and Query. With a typical RDBMS system, these layers are “glued” together with the overall application, for example, SQL Server or Oracle. However, in Hadoop these layers work independently allowing for multiple access to each layer; meaning super-scalable performance.
Exploring Data between the Data Warehouse and Hadoop Cluster
Often there is an unknown quality or value in the Hadoop data. To start to identify value or explore the possibility of gaining new insight from the Hadoop data, it is useful to be able to query the data directly and alongside the existing data warehouse. To query by conformed dimensions, for example, is extremely powerful and can help to query Hadoop data based on well-governed dimension data.
This “exploration” can be relatively slow, compared to simply querying Hadoop with Hive or Impala directly, or by queries against a dimensional modelled data warehouse. However, this gives us an opportunity to explore data before we worry about leveraging an ETL process to extract, transform and load the data into our ultimate data warehouse.
To do this exploration there are two main options:
Option 1 – Mash Ups
By leveraging tools such as Power BI (Power Query and Power Pivot) or Alteryx Designer, you are able to bring together data from a Hadoop cluster and an RDBMS data warehouse. The data can be modelled and calculations added. Finally, the data can be queried to start to identify possible insights.
Option 2 – Direct Querying
There are some technologies, such as Microsoft Polybase or Teradata QueryGrid, that allow you to leverage SQL query language to add temporary structure to Hadoop data and join to data warehouse data. My hope from Microsoft is that Polybase is bought from the MPP appliance, APS, and into SMP SQL Server in its next release. This technology is perfect for people not wishing to learn Java, Python, Sqoop and Linux.
Extending the Data Warehouse
The explore options above are useful but limited. Performance will be limited by the Hadoop Cluster and a lack of structure on the data or by the RDBMS data warehouse. If insight is shown through the exploration then the next logical step will be to bring useful data together into a single data warehouse.
Initially you may wish to use existing ETL tools, such as SSIS, Information Builders, or go directly to what these tools often leverage which is Sqoop. This will allow you to bring data from the Hadoop cluster and then you can use Pig, for example, to transform the data into a dimensional model in your existing RDBMS data warehouse. This allows you to benefit from the proven performance of a dimensional model. I refer to this data as your “known unknowns”.
Secondly, you may wish to move your data warehouse or, more often, create your new data warehouse in Hadoop. This can be a sensible option when you compare the performance of the Hadoop architecture compared to RDBMS standard architecture. You can also still leverage your SQL skills using tools such as Hive or Impala to analyse the data. However, to further improve performance, you can add some semi-permanent structure to the data using Parquet. Parquet is a file format that uses columnar methods similar to existing in-memory columnar engines such as Vertipaq. This will allow us to apply dimensional modelling techniques to our data and benefit from conformed dimensions, for example.
In Summary
Ultimately, we should not ignore Big Data and Hadoop. The “Internet of Things” alone will mean the volume; variety and velocity of data available to our businesses will stretch traditional RDBMS data warehouses to the maximum. Will they cope? Do existing techniques, such as dimensional modelling, still work? The answer is probably yes, to both. Dr Ralph Kimball, in his webinar series with Cloudera last year, likened it to XML data when it first arrived. It was tough to manage and it took RDBMS vendors 10 years to integrate XML into their applications. However, why wait? With the tools mentioned in the exploration section, and there are many more, you have the ability to easily investigate Big Data and mix it up with your existing data warehouse. As BI professionals the more value we can add to the business will make investment into better hardware, more storage, advanced tools far easier to access.
References and Useful Links:
Cloudera and Ralph Kimball: http://cloudera.com/content/cloudera/en/resources/library/recordedwebinar/building-a-hadoop-data-warehouse-video.html
SSIS and Hadoop: http://sqlmag.com/blog/use-ssis-etl-hadoop
Power Query and Hadoop: http://msbiacademy.com/?p=6641
Microsoft Polybase: http://blogs.technet.com/b/dataplatforminsider/archive/2014/04/30/change-the-game-with-aps-and-polybase.aspx
Introduction to Flume and Sqoop: http://www.guru99.com/introduction-to-flume-and-sqoop.html
Parquet (Hadoop): http://parquet.incubator.apache.org/