
This post is the second in a series on transactional replication. In the first post I described general performance tips for transactional replication. In this post I’ll explore one method that we used to significantly improve the performance and scalability of transactional replication.
The method that was employed to deliver the results was to partition the published database using partitioned views. Whilst it might at first appear that horizontally partitioned views is unrelated to transactional replication I’ll show in this post how it provides a mechanism for parallelizing the log reader and distribution agents to offer significant performance gains. For those wanting a summary of partitioned views you can refer to post on partitioned views.
The Problem
The motivation to write this post came from one of Coeo’s Remote DBA customers, who makes extensive use of transactional replication to offload search functionality off a 700 GB OLTP database. In the case of this customer we saw a disproportionally higher number of product searches compared to orders, which isn’t an unusual situation on online ordering systems. On this OLTP system customer demand for products would drive price fluctuations for tens of millions (or even hundreds of millions) of similar product types. Naturally updates to tens of millions of rows on the publisher, need to be replicated to the subscribers.
Unfortunately transactional replication is very well suited to small, discrete, transactions; whereas large transactions (i.e. Transactions that update hundreds of millions of rows) aren’t well suited for transactional replication (please review the first post (link here) for details on why this is). Consequently, during price updates, replication latency would climb to such a point that product prices were not being accurately represented to users during searches (i.e. at the subscribers).
Under these conditions replication latency was having a significant and direct impact on revenue and, of course, the user experience. At its worst replication latency would increase to as much as 12 hours and, with a highly transactional database, catching up could take as much as 2 days; so much so that it was often quicker to reinitialize the subscribers, which would take 27 hours.
As such, there was a big desire to significantly improve on the performance of replication by 1000% or more.
In this post I’ll describe the solution that the we came up with which not only achieves these significant performance gains, but a solution that provides the foundation for future scalability that will allow future increases in performance as the data grows.
Parallelizing Replication
It became apparent that general performance tips had been exhausted and whilst we did gain performance improvements using these, the gains that they provided were measured with double-digit percentage points.
We believed that the only way to gain performance improvements of several orders of magnitude was to (somehow) parallelize replication. Imagine if we could have 4 log reader agents and 4 distribution agents, all working on the same published data at the same time.
Now, whilst we couldn’t (technically speaking) parallelize replication in this way, we could parallelize the data, so to speak. We therefore decided to extend the use of horizontally partitioned views (as discussed in this link) by creating each member table in a different database, as illustrated in the image below.
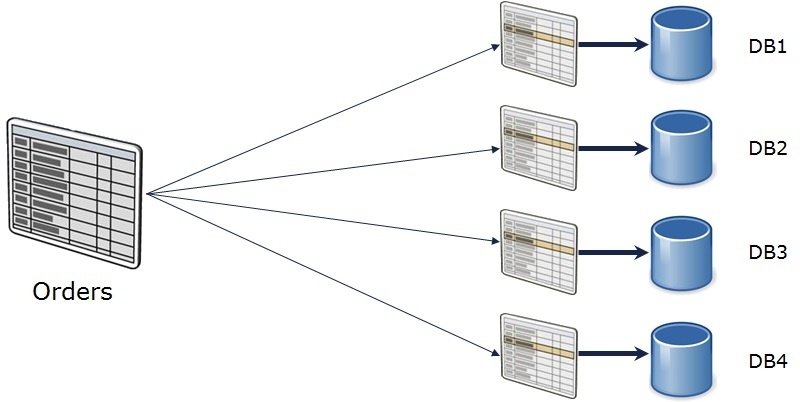
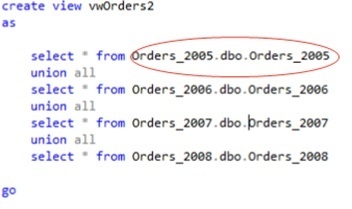
The accompanying view could be created using the T-SQL below. Note how the reference to the member tables is a fully-qualified name that includes the database in which the table exists.
Making this small change dramatically changes our replication solution. Now that our data is split across multiple databases, we can independently publish each database. The implication of this is that we can now have multiple log readers and multiple distribution agents operating on the same set of data as before, except the data has now been split.
There’s an important point that should be made about check constraints and replication. Whilst you can include the check constraint in a publication the constraint is stored as “is_not_trusted” and will not be used at all on the subscriber. As a result, on replicated tables with check constraints, you should always create the check constraints manually after delivering the snapshot to the subscribers.
In the case of our customer a partitioning key of date was not particularly useful. Instead a partitioning key that related to product brand was chosen in such a way that different product brands were restricted to a single database. This was particularly useful because most of the tables in the database referred to brand, which meant that most of the tables could be partitioned. It was also useful because all data updates were restricted to one brand at a time. This meant that updates to any one brand would not negatively impact the whole data set, instead only affecting 25% of the data.
It’s important to note that splitting up the data in this way does have potential to reduce transactional consistency at the subscribers for transactions that span multiple databases. However, by splitting up the data in such a way that transactions don’t span multiple databases, this problem can be avoided.
Results
Architecturally we went from a vanilla implementation of transactional replication to one in which we had many log readers and distribution agents for the same data set. This offered obvious parallel work stream potential that didn’t exist before.
It also meant that maintenance that was previously difficult to perform was much easier. We previously struggled to perform regular DBCC checks and index maintenance on a 700 GB database. However, now that each individual database was much smaller, it opened up a number of options for maintenance.
The new architecture also simplified the scalability options for us. As the data grows we just need to add another database and incorporate it into the view.
It should be mentioned that the changes were implemented in such a way that the partitioned views were named identically to the old (underlying) tables. This decision meant that the change was completely transparent to the calling application and users, which was a massive benefit.
Splitting the data as described offered a surprising improvement in performance. Overall we saw performances gains in excess of 1000%. As an example reinitializing, which would ordinarily take 27 hours, was down to 2 hours. The full reasons underlying such a big performance gain are not fully understood but there are a few clues that we were able to draw upon. Firstly the CPU increase on the distributor was increased by more than a factor of 4. This would indicate that the parallelization of log readers and distribution agents meant that these agents were, collectively, able to tap into more CPU resources on the box than they previously were. It’s also important to note that performance vs data size is not necessarily a linear relationship. In other words, if data size doubles it’s not necessarily the case that performance is halved for queries against such a data set.
Scaling Out
It should be noted that we could scale out even further by creating distributed partitioned views, where the tables reside on a completely different SQL Server instance. Separating data across different instances offers a further advantage in that each instance is a completely different publisher, which could potentially make use of a different distributor, on different hardware. So not only are we parallelizing the distribution agent but we’re in a position to parallelize it across different hardware.
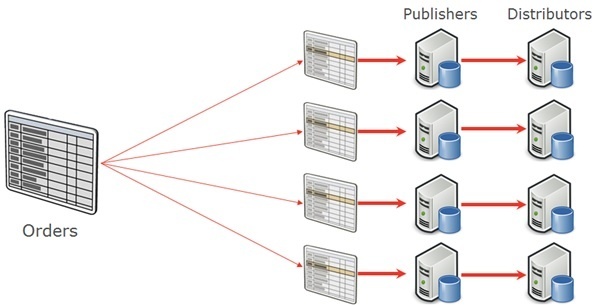
Although the performance gains achieved by scaling up on a single instance were sufficient for our current-day needs, the opportunity to scale out onto other instances offers interesting future choices for when resources on existing hardware are exhausted.
Whilst it is easy to say this in hindsight, faced with a similar architecture and having to start from scratch, we would certainly consider partitioned views as a possible architecture from the very beginning. The general performances tips mentioned earlier should still be considered but it’s important to be aware that the level of performance increases that can be gained using these tips are measured in single or double-digit percentage points. On the other hand, partitioning the data offers increases measured by orders of magnitude and, of course, offers future growth potential which isn’t possible otherwise.
I would like to take this opportunity to mention Koen Reijns and Jeffrey Verheul (Twitter: @DevJef), who were responsible for originally conceiving of the possibility and for successfully implementing this solution in a short time of 2 weeks.