
In this post I want to provide a brief overview of horizontally partitioned views. One of the reasons for covering partitioned views is that it provides a mechanism for “sharding” data in such a way as to provide significant performance benefits, which I’ll explore in a future post.
Scaling Up
The basic idea behind partitioned views is to split a large set of data that is unwieldy and difficult to manage (as well as potentially slow to query) and splitting it up into smaller chunks of data. In addition to this, partitioned views can be implemented in such a way as to hide the existence of the views (from a calling application or user).
One such way of splitting up the data in SQL Server is to use horizontally partitioned views, which is best described with an example.
Consider the following example, which illustrates a large Orders table called tblLargeOrders (say, with 1 billion rows).
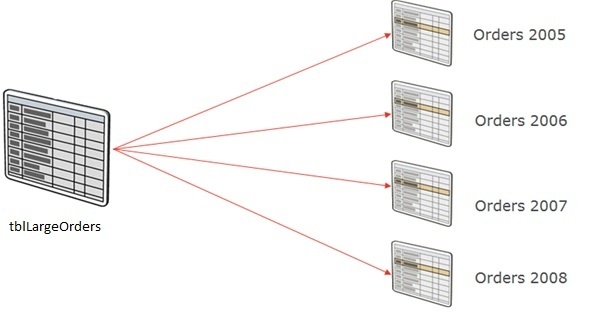
In the image above we can see that the tblLargeOrders table has been (conceptually) split into 4 smaller tables, which each contain orders for a specific year.
In order to take the above concept further and physically implement it we would need to first create each of the 4 smaller tables, which are sometimes referred to as member tables.
The CREATE TABLE statement below shows how we would physically implement one of the above member tables.
CREATE TABLE [dbo].[Orders_2005](
[OrderID] [int] NOT NULL,
[OrderDetailId] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[OrderDate] [datetime] NOT NULL CHECK ([OrderDate]>='1 Jan 2005 00:00:00.000' AND [OrderDate]<'1 Jan 2006 00:00:00.000'),
CONSTRAINT [PK_Order2005_OrderID] PRIMARY KEY CLUSTERED ([OrderID] ASC,[OrderDetailId] ASC,[OrderDate] ASC)
)
In the above CREATE TABLE example, the orders for the year 2005 are contained in this table. Note how the check constraint defines the allowable range of data in this table. Whilst the check constraint isn’t strictly required, as we’ll see later, it is important for the query optimizer. Also note that the data in the table has been partitioned by OrderDate – this column is known as the partition column (or partition key).
After physically creating all of the member tables, the next step in physically implementing the partitioned view is to create a view. Shown below is an example of a horizontally partitioned view that includes the union of all of the member tables illustrated in the above image.
create view [dbo].[vwOrders]
as
select * from Orders_2005
union all
select * from Orders_2006
union all
select * from Orders_2007
union all
select * from Orders_2008
go
The view (as created above) is the union of each of the member tables so it is in effect no different (in the logical sense) to the original tblLargeOrders table. The only difference is that the data is physically held in different tables. The physical location of the tables however is abstracted from anyone that uses the view to select data.
At this stage each of the member tables are empty and contain no data, so the next step in physically implementing the view is to populate the member tables with data.
This can be simply done with the following insert statement:
insert into vwOrders(OrderID, OrderDetailId, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount, OrderDate)
select * from tblLargeOrders
As explained above, the underlying member tables are abstracted from anyone using the view, so inserting into the view results in the data being inserted into the relevant tables that comprise the view. Similarly if you wanted to update the underlying tables you would just update the view.
There are however a number of important considerations that need to be taken into account when updating partitioned views.
- Partition column must be part of the primary key
- Identity columns are not allowed in member tables
- Timestamp columns are not allowed in member tables
- Cannot insert into a partitioned view if the member table has a self-join
- All columns must be explicitly referenced in any insert statements
Performance Benefits
Consider the follow T-SQL statement (and its corresponding execution plan) that selects data for the month of December 2005 from the vwOrders view.
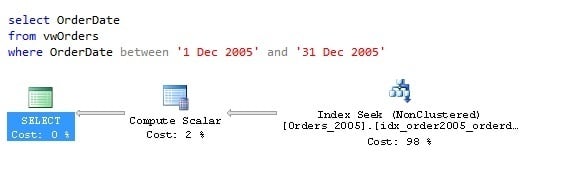
Note how the optimizer chooses to perform an index seek on only the Orders_2005 table. This is only possible because the check constraint informs the optimizer that this is the only table that needs to be used to satisfy the query predicate.
Be aware that if the query running against the view contains parameters the resulting execution plan might make you think that all tables are being used. See the below example:
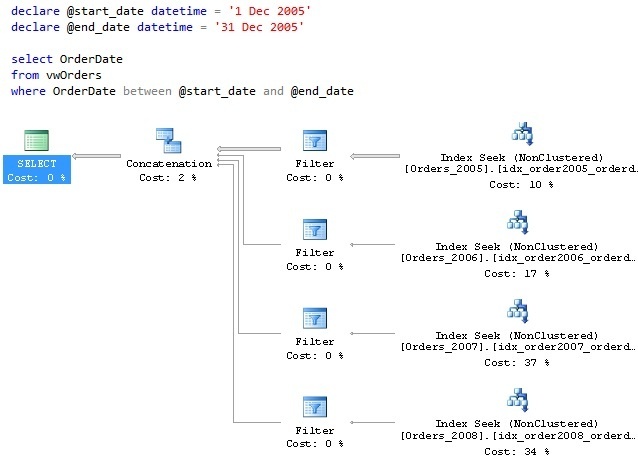
In the above example the same query as in the previous example is being used. However, in this instance, parameters are passed through instead of inline values.
As you can see, it appears that an index seek is being performed on all member tables, as opposed to just the Orders_2005 table. However if you hover over the index scan operator on the Orders_2008 table you’ll see the following:
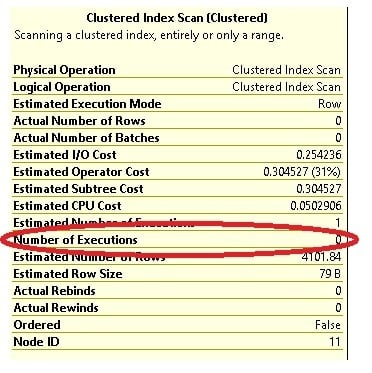
As can be seen, the number of executions for this operator is 0. In fact the only operator that has a value of 1 for “number of executions” is the index seek on the Orders_2005 table. So whilst it may appear that the optimizer is incorrectly using all the member tables it is only making use of the member table(s) that it needs to in order to satisfy the query predicate.
By partitioning the data as described we’ve being able to reduce the size of the problem that the query optimizer has to deal with and gained a number of other advantages. Maintenance tasks, such as index rebuilds that might have been difficult to perform on a billion-row table, can be made possible. Separation of data also means that performance problems that affect one partition of data, needn’t impact other partitions of data.
Partitioning can be taken further by physically implementing the member tables on different databases or even instance, which is something that I’ll explore in a future post.