
It’s been a while since I last wrote about my favourite piece of tech, which is not the latest neither sometimes the greatest, but we’ve been together for over a decade now and I still love it. That is the SQL Server engine.
Here at Coeo, in the Dedicated Support team, we have to deal with a wide range of SQL Server features and architectures, which is what makes our day to day always challenging and never boring.
One of those features is partitioning.

Even though partitioning has been part of the SQL Server Engine for a number of years and versions, it’s not that common to see customers using it, so I decided to make a list with 5 cool things you can do when your data is partitioned:
- Move files to another location without affecting the availability of the database
- Rebuild part of our data using different compression/fill factor settings
- Setting part of our data to be READ_ONLY
- Quickly remove old data without incurring in high log usage
- SQL Server 2016 onwards TRUNCATE TABLE WITH (PARTITIONS))
- Pre 2016, partition switching
- Partial backups and restores
Setting up the playground
To carry out all the above, we need to create a partitioned table since the WideWorldImporters sample database doesn’t have any when you download it.
But that’s good, because you’ll also see what it takes to be able to create partitioned tables.
We need some new Filegroups, a Partition Function and a Partition Scheme to then create a partitioned table. Let’s go for it.
--===================================
-- Create partition function and partition scheme
--===================================
USE [WideWorldImporters]
GO
CREATE PARTITION FUNCTION pf_ArchiveYearly (DATE)
AS RANGE RIGHT FOR VALUES
( '20140101'
, '20150101'
, '20160101'
, '20170101')
-- Create filegroups and files for each of the ranges defined above
ALTER DATABASE WideWorldImporters
ADD FILEGROUP [Archive_pre_2014];
ALTER DATABASE WideWorldImporters
ADD FILE (NAME=Archive_pre_2014, FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQL2019\MSSQL\DATA\Archive_pre_2014.ndf')
TO FILEGROUP [Archive_pre_2014];
ALTER DATABASE WideWorldImporters
ADD FILEGROUP [Archive_2014]
ALTER DATABASE WideWorldImporters
ADD FILE (NAME=Archive_2014, FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQL2019\MSSQL\DATA\Archive_2014.ndf')
TO FILEGROUP [Archive_2014]
ALTER DATABASE WideWorldImporters
ADD FILEGROUP [Archive_2015]
ALTER DATABASE WideWorldImporters
ADD FILE (NAME=Archive_2015, FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQL2019\MSSQL\DATA\Archive_2015.ndf')
TO FILEGROUP [Archive_2015]
ALTER DATABASE WideWorldImporters ADD FILEGROUP [Archive_2016]
ALTER DATABASE WideWorldImporters
ADD FILE (NAME=Archive_2016, FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQL2019\MSSQL\DATA\Archive_2016.ndf')
TO FILEGROUP [Archive_2016]
ALTER DATABASE WideWorldImporters ADD FILEGROUP [Archive_2017]
ALTER DATABASE WideWorldImporters
ADD FILE (NAME=Archive_2017, FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQL2019\MSSQL\DATA\Archive_2017.ndf')
TO FILEGROUP [Archive_2017]
-- let's map the filegroups to the ranges defined previously '
CREATE PARTITION SCHEME ps_ArchiveYearly
AS PARTITION pf_ArchiveYearly
TO (Archive_pre_2014, Archive_2014, Archive_2015, Archive_2016, Archive_2017)
-- Start partitioning
-- Since the original table is referenced by FK, Let's make this simple and dump all content in a new table '
USE [WideWorldImporters]
GO
CREATE TABLE [Sales].[Orders_Partitioned](
[OrderID] [int] NOT NULL,
[CustomerID] [int] NOT NULL,
[SalespersonPersonID] [int] NOT NULL,
[PickedByPersonID] [int] NULL,
[ContactPersonID] [int] NOT NULL,
[BackorderOrderID] [int] NULL,
[OrderDate] [date] NOT NULL,
[ExpectedDeliveryDate] [date] NOT NULL,
[CustomerPurchaseOrderNumber] [nvarchar](20) NULL,
[IsUndersupplyBackordered] [bit] NOT NULL,
[Comments] [nvarchar](max) NULL,
[DeliveryInstructions] [nvarchar](max) NULL,
[InternalComments] [nvarchar](max) NULL,
[PickingCompletedWhen] [datetime2](7) NULL,
[LastEditedBy] [int] NOT NULL,
[LastEditedWhen] [datetime2](7) NOT NULL,
CONSTRAINT [PK_Sales_Orders_Partitioned]
PRIMARY KEY CLUSTERED ([OrderID] ASC, OrderDate ASC) ON ps_ArchiveYearly(OrderDate)
) ON ps_ArchiveYearly(OrderDate)
GO
-- Load the table
INSERT INTO [Sales].[Orders_Partitioned]
(OrderID
, CustomerID
, SalespersonPersonID
, PickedByPersonID
, ContactPersonID
, BackorderOrderID
, OrderDate
, ExpectedDeliveryDate
, CustomerPurchaseOrderNumber
, IsUndersupplyBackordered
, Comments
, DeliveryInstructions
, InternalComments
, PickingCompletedWhen
, LastEditedBy
, LastEditedWhen)
SELECT OrderID
, CustomerID
, SalespersonPersonID
, PickedByPersonID
, ContactPersonID
, BackorderOrderID
, OrderDate
, ExpectedDeliveryDate
, CustomerPurchaseOrderNumber
, IsUndersupplyBackordered
, Comments
, DeliveryInstructions
, InternalComments
, PickingCompletedWhen
, LastEditedBy
, LastEditedWhen
FROM sales.Orders
GO
-- See how the data is distributed in our table
SELECT ix.object_id
, OBJECT_NAME(ix.object_id) AS table_name
, ix.name
, ix.index_id
, ix.type_desc
, ps.name
, pf.name
, p.rows
, au.total_pages
, p.data_compression_desc
, fg.name AS filegroup_name
--, *
FROM sys.indexes AS ix
INNER JOIN sys.partition_schemes AS ps
ON ps.data_space_id = ix.data_space_id
INNER JOIN sys.partition_functions AS pf
ON ps.function_id = pf.function_id
INNER JOIN sys.partitions AS p
ON p.object_id = ix.object_id
AND p.index_id = ix.index_id
INNER JOIN sys.allocation_units AS au
ON au.container_id = p.hobt_id
AND au.type_desc = 'IN_ROW_DATA'
INNER JOIN sys.filegroups AS fg
ON fg.data_space_id = au.data_space_id
WHERE ix.object_id = OBJECT_ID('Sales.Orders_Partitioned')
ORDER BY ix.type
, ix.index_id
, p.partition_number;
GO

Once we have created our partitioned table, we’re ready to see the cool stuff.
Rebuild part of our data using different index settings
One of the never-ending fights in the life of a DBA is removing index fragmentation, we know it and we live with it, but if you want to archive data which will not be modified, do you really need to keep that fill factor to 80%? probably not. You might want to compress it as well.
I would pack as much data as possible in the minimum space, just like the hand luggage of a low-cost airline passenger, to save some money.
Different partitions can be rebuilt using different index settings, like compression, fill factor or index padding to suit our needs.
See how this can be easily done.
--===================================================================
-- REBUILD partitions with different compression settings
--===================================================================
USE [WideWorldImporters]
ALTER INDEX [PK_Sales_Orders_Partitioned] ON Sales.Orders_Partitioned
REBUILD PARTITION = 2 WITH (DATA_COMPRESSION = PAGE)
-- Check the new settings
SELECT ix.object_id
, OBJECT_NAME(ix.object_id) AS table_name
, ix.name
, ix.index_id
, ix.type_desc
, ps.name
, pf.name
, p.rows
, au.total_pages
, p.partition_number
, p.data_compression_desc
, fg.name AS filegroup_name
, fg.is_read_only
--, *
FROM sys.indexes AS ix
INNER JOIN sys.partition_schemes AS ps
ON ps.data_space_id = ix.data_space_id
INNER JOIN sys.partition_functions AS pf
ON ps.function_id = pf.function_id
INNER JOIN sys.partitions AS p
ON p.object_id = ix.object_id
AND p.index_id = ix.index_id
INNER JOIN sys.allocation_units AS au
ON au.container_id = p.hobt_id
AND au.type_desc = 'IN_ROW_DATA'
INNER JOIN sys.filegroups AS fg
ON fg.data_space_id = au.data_space_id
WHERE ix.object_id = OBJECT_ID('Sales.Orders_Partitioned')
ORDER BY ix.type
, ix.index_id
, p.partition_number;

You can see the Filegroup Archive_2014 is about half the pages of the others, even though the number of rows is pretty similar.
Move Database Files to Different Locations
We know that moving database files to a different location is possible, but most of the time incurs some downtime to physically move the files.
However, if our data is partitioned, we can move only the files we want while the rest of the database is still available and ready to serve the data.
A good example of a use case: moving data older than X days/months/years to cheaper storage so we can reduce our running costs.
Just as a little reminder, in SQL Server we can’t choose in which file the data will be stored, but can choose which filegroup the data will be stored, which will determine in which file(s) the data will end up.
Let’s illustrate this with an example using the WideWorldImporters database and move a file while the database is still online.
--===================================================================
-- Move old filegroups to a different location
--===================================================================
USE [WideWorldImporters]
SELECT f.file_id
, f.type_desc
, f.name
, f.physical_name
, f.state_desc
, f.size
, f.max_size
, f.is_read_only
FROM sys.database_files AS f
-- C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQL2019\MSSQL\DATA\Archive_pre_2014.ndf
ALTER DATABASE [WideWorldImporters] MODIFY FILE (NAME='Archive_pre_2014', FILENAME='D:\SQL\DATA\Archive_pre_2014.ndf')
-- The file "Archive_pre_2014" has been modified in the system catalog. The new path will be used the next time the database is started.
-- Take the file OFFLINE, so we can physically move it
ALTER DATABASE [WideWorldImporters] MODIFY FILE (NAME='Archive_pre_2014', OFFLINE)
-- Check the status
SELECT f.file_id
, f.type_desc
, f.name
, f.physical_name
, f.state_desc
, f.size
, f.max_size
, f.is_read_only
FROM sys.database_files AS f
WHERE f.name = 'Archive_pre_2014'
-- Data within that file is not available
SELECT * FROM Sales.Orders_Partitioned
WHERE OrderDate < '20140101'
-- Msg 679, Level 16, State 1, Line 385
-- One of the partitions of index 'PK_Sales_Orders_Partitioned' for table 'Sales.Orders_Partitioned'(partition ID 72057594062110720) resides on a filegroup ("Archive_pre_2014") that cannot be accessed because it is offline, restoring, or defunct. This may limit the query result.
-- Move the file to the new location
EXECUTE xp_cmdshell 'robocopy /mov "C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQL2019\MSSQL\DATA" "D:\SQL\DATA" "Archive_pre_2014.ndf"'
-- Bring the file ONLINE
USE master
RESTORE DATABASE [WideWorldImporters] FILE='Archive_pre_2014' WITH RECOVERY
GO
-- RESTORE DATABASE successfully processed 0 pages in 0.011 seconds (0.000 MB/sec).
-- Check the file and the data
USE WideWorldImporters
SELECT f.file_id
, f.type_desc
, f.name
, f.physical_name
, f.state_desc
, f.size
, f.max_size
, f.is_read_only
FROM sys.database_files AS f
SELECT * FROM Sales.Orders_Partitioned
WHERE OrderDate < '20140101'
-- All data is good now!
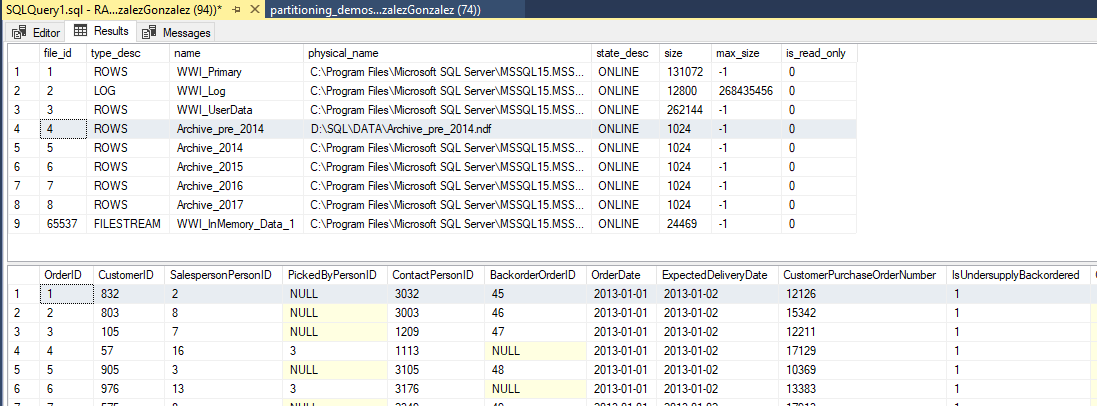
Moving files that belong to a filegroup other than PRIMARY can be done while the database remains ONLINE (not the filegroup we’re moving, obviously), which is far more convenient than taking the whole database OFFLINE.
Making parts of our data READ_ONLY
Once we have rebuilt that old data to minimise its footprint and moved it to a cheaper storage tier, if we know no one will have to modify it, it’d be a good idea to make it READ_ONLY.
By making the data READ_ONLY, we can not only prevent accidental deletion or modification, but also reduce the workload required to maintain it, because as we’ve seen before, we can action index maintenance only on the READ_WRITE parts (partitions) of the data where fragmentation might still happen.
You would need to be more selective when rebuilding your indexes as if any partition is stored in a READ_ONLY filegroup, you’ll get an error.
In the next demo, you can see how it can be done.
--===================================================================
-- Set the filegroup to be READ_ONLY
--===================================================================
ALTER DATABASE [WideWorldImporters] MODIFY FILEGROUP Archive_pre_2014 READ_ONLY
SELECT TOP(1) * FROM Sales.Orders_Partitioned
WHERE OrderDate = '20130101'
-- 1
UPDATE Sales.Orders_Partitioned
SET InternalComments = 'Update READ_ONLY'
WHERE OrderID = 1
-- Msg 652, Level 16, State 1, Line 480
-- The index "PK_Sales_Orders_Partitioned" for table "Sales.Orders_Partitioned"
-- (RowsetId 72057594062110720) resides on a read-only filegroup ("Archive_pre_2014"),
-- which cannot be modified.
Now the data is safe and doesn't need further maintenance, so we can use that computing for better things.
Quickly remove old data without incurring in high log usage
While we know the value of data, sometimes it’s not healthy for our databases to keep it all just for the sake of it.
A good retention policy in place along with the right tools, can make this a trivial task instead of a heavy burden.
Deleting records can be an expensive task and depending on the approach we take, it will cause major issues because it can lock the whole table while executing. And if this happens in that very busy table where you generate millions of records a day, it can be catastrophic.
If you use partitioning, you have two options depending in which version you’re using. From SQL Server 2016, you can TRUNCATE partitions independently, like this:
--===================================================================
-- Truncate one or more Partitions
--===================================================================
USE [WideWorldImporters]
-- Check current data distribution
SELECT ix.object_id
, OBJECT_NAME(ix.object_id) AS table_name
, ix.name
, ix.index_id
, ix.type_desc
, ps.name
, pf.name
, p.rows
, p.partition_number
, p.data_compression_desc
, fg.name AS filegroup_name
, fg.is_read_only
--, *
FROM sys.indexes AS ix
INNER JOIN sys.partition_schemes AS ps
ON ps.data_space_id = ix.data_space_id
INNER JOIN sys.partition_functions AS pf
ON ps.function_id = pf.function_id
INNER JOIN sys.partitions AS p
ON p.object_id = ix.object_id
AND p.index_id = ix.index_id
INNER JOIN sys.allocation_units AS au
ON au.container_id = p.hobt_id
AND au.type_desc = 'IN_ROW_DATA'
INNER JOIN sys.filegroups AS fg
ON fg.data_space_id = au.data_space_id
WHERE ix.object_id = OBJECT_ID('Sales.Orders_Partitioned')
ORDER BY ix.type
, ix.index_id
, p.partition_number;
-- TRUNCATE one partition or a range of partitions
TRUNCATE TABLE Sales.Orders_Partitioned WITH(PARTITIONS(3))
-- TRUNCATE TABLE Sales.Orders_Partitioned WITH(PARTITIONS(3 TO 4))
-- Check again with the first query

But if your shop still lives in the past, don’t worry, you still can work around it using a technique called PARTITION SWITCHING, where you can change the table the data belongs to, then TRUNCATE that new table.
Follow this example.
--===================================================================
-- SWITCH PARTITION and TRUNCATE
--===================================================================
USE [WideWorldImporters]
-- All filegroups need to be READ_WRITE to be able to create a new table
ALTER DATABASE [WideWorldImporters] MODIFY FILEGROUP Archive_pre_2014 READ_WRITE
-- Create the dummy table
CREATE TABLE [Sales].[Orders_Dummy](
[OrderID] [int] NOT NULL,
[CustomerID] [int] NOT NULL,
[SalespersonPersonID] [int] NOT NULL,
[PickedByPersonID] [int] NULL,
[ContactPersonID] [int] NOT NULL,
[BackorderOrderID] [int] NULL,
[OrderDate] [date] NOT NULL,
[ExpectedDeliveryDate] [date] NOT NULL,
[CustomerPurchaseOrderNumber] [nvarchar](20) NULL,
[IsUndersupplyBackordered] [bit] NOT NULL,
[Comments] [nvarchar](max) NULL,
[DeliveryInstructions] [nvarchar](max) NULL,
[InternalComments] [nvarchar](max) NULL,
[PickingCompletedWhen] [datetime2](7) NULL,
[LastEditedBy] [int] NOT NULL,
[LastEditedWhen] [datetime2](7) NOT NULL,
CONSTRAINT [PK_Sales_Orders_Dummy] PRIMARY KEY CLUSTERED
(
[OrderID] ASC
, [OrderDate] ASC
) ON ps_ArchiveYearly(OrderDate)
) ON ps_ArchiveYearly(OrderDate)
GO
-- Check data distribution
SELECT ix.object_id
, OBJECT_NAME(ix.object_id) AS table_name
, ix.name
, ix.index_id
, ix.type_desc
, ps.name
, pf.name
, p.rows
, p.partition_number
, p.data_compression_desc
, fg.name AS filegroup_name
, fg.is_read_only
--, *
FROM sys.indexes AS ix
INNER JOIN sys.partition_schemes AS ps
ON ps.data_space_id = ix.data_space_id
INNER JOIN sys.partition_functions AS pf
ON ps.function_id = pf.function_id
INNER JOIN sys.partitions AS p
ON p.object_id = ix.object_id
AND p.index_id = ix.index_id
INNER JOIN sys.allocation_units AS au
ON au.container_id = p.hobt_id
AND au.type_desc = 'IN_ROW_DATA'
INNER JOIN sys.filegroups AS fg
ON fg.data_space_id = au.data_space_id
WHERE ix.object_id IN (OBJECT_ID('Sales.Orders_Partitioned'), OBJECT_ID('Sales.Orders_Dummy'))
ORDER BY table_name
, ix.type
, ix.index_id
, p.partition_number;
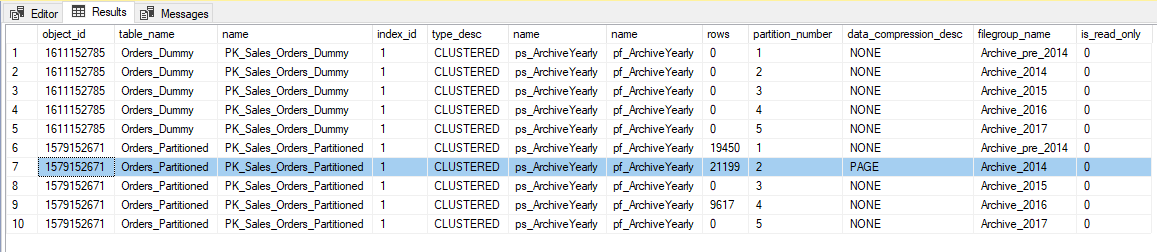
-- Partitions need to have the same data compression and the filegroups to be READ_WRITE ALTER TABLE sales.Orders_Partitioned SWITCH PARTITION 2 TO Sales.Orders_Dummy PARTITION 2 --Msg 11406, Level 16, State 1, Line 465 --ALTER TABLE SWITCH statement failed. Source and target partitions have different values for the DATA_COMPRESSION option. ALTER INDEX [PK_Sales_Orders_Dummy] ON Sales.Orders_Dummy REBUILD PARTITION = 2 WITH (DATA_COMPRESSION = PAGE) ALTER TABLE sales.Orders_Partitioned SWITCH PARTITION 2 TO Sales.Orders_Dummy PARTITION 2 -- Now check the data with the query above -- The data we want to get rid of is now in the dummy table, so we can just TRUNCATE it TRUNCATE TABLE Sales.Orders_Dummy GO
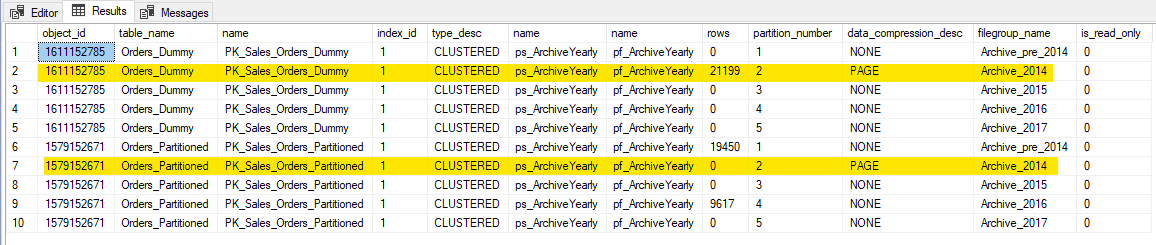
You can see the data has magically moved from one table to the other and it's ready to be truncated.
Removing data using TRUNCATE instead of DELETE is a lighter approach and should be always considered.
Partial Backups and Restores
Once SQL Server databases grow into the Terabytes, performing FULL backups can be one of the most painful tasks running on your server.
On the other hand, you know that only a fraction of the data is new or potentially updated, so, why take backups over and over of the same immutable data? That seems a waste.
If we combine partitioning and distributing our data in different filegroups and make sure READ_ONLY data is marked as such, we can take PARTIAL backups of the READ_WRITE filegroups regularly but we only need to backup the READ_ONLY data once, to be able to restore the whole database, isn’t it cool?
--===================================================================
-- Partial Backups and Restore
--===================================================================
USE [WideWorldImporters]
-- We will do now:
-- - PARTIAL BACKUP and RESTORE
-- - FILE/FILEGROUP backups
-- - READ_WRITE_FILEGROUPS backups
--
-- Let's make all data before 2016 Read only.'
ALTER DATABASE [WideWorldImporters] MODIFY FILEGROUP Archive_pre_2014 READ_ONLY
ALTER DATABASE [WideWorldImporters] MODIFY FILEGROUP Archive_2014 READ_ONLY
ALTER DATABASE [WideWorldImporters] MODIFY FILEGROUP Archive_2015 READ_ONLY
--======================================================
-- Let's make some backups '
--======================================================
-- READ_WRITE filegroups
BACKUP DATABASE WideWorldImporters
READ_WRITE_FILEGROUPS TO DISK = N'WideWorldImporters_FULL_PARTIAL_0001.bak' WITH CHECKSUM, COMPRESSION, INIT
GO
-- READ_ONLY filegroups
BACKUP DATABASE WideWorldImporters FILEGROUP = 'Archive_pre_2014'
TO DISK = N'WideWorldImporters_FILEGROUP_Archive_pre_2014.bak' WITH CHECKSUM, COMPRESSION, INIT
BACKUP DATABASE WideWorldImporters FILEGROUP = 'Archive_2014'
TO DISK = N'WideWorldImporters_FILEGROUP_Archive_2014.bak' WITH CHECKSUM, COMPRESSION, INIT
BACKUP DATABASE WideWorldImporters FILEGROUP = 'Archive_2015'
TO DISK = N'WideWorldImporters_FILEGROUP_Archive_2015.bak' WITH CHECKSUM, COMPRESSION, INIT
GO
-- READ_WRITE filegroups DIFFERENTIAL
BACKUP DATABASE WideWorldImporters
READ_WRITE_FILEGROUPS TO DISK = N'WideWorldImporters_DIFF_PARTIAL_0001.bak' WITH CHECKSUM, COMPRESSION, DIFFERENTIAL, INIT
--==========================================
-- We have:
-- 1 backup for REAR_WRITE
-- 1 backup for each READ_ONLY
-- 1 Diff backup for READ_WRITE
--==========================================
USE [master]
GO
IF DB_ID('WideWorldImporters') IS NOT NULL BEGIN
ALTER DATABASE [WideWorldImporters] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [WideWorldImporters]
END
GO
-- RESTORE FILELISTONLY FROM DISK = 'WideWorldImporters_FULL_PARTIAL_0001.bak'
-- RESTORE the FULL PARTIAL WITH NORECOVERY
RESTORE DATABASE WideWorldImporters
FILEGROUP = 'PRIMARY'
, FILEGROUP = 'USERDATA'
, FILEGROUP = 'Archive_2016'
, FILEGROUP = 'Archive_2017'
, FILEGROUP = 'WWI_InMemory_Data'
FROM DISK = 'WideWorldImporters_FULL_PARTIAL_0001.bak'
WITH PARTIAL, NORECOVERY
-- RESTORE the DIFF PARTIAL WITH RECOVERY
RESTORE DATABASE WideWorldImporters
FROM DISK = N'WideWorldImporters_DIFF_PARTIAL_0001.bak'
WITH RECOVERY
--==========================================
-- All READ_WRITE filegroups are now online
--==========================================
USE WideWorldImporters
SELECT fg.name
, f.name
, f.state_desc
FROM sys.filegroups AS fg
INNER JOIN sys.database_files AS f
ON f.data_space_id = fg.data_space_id
At this point, we have the database up and running and only the old read only data is not available.
--==========================================
-- Check data distribution
--==========================================
SELECT ix.object_id
, OBJECT_NAME(ix.object_id) AS table_name
, ix.name
, ix.index_id
, ix.type_desc
, ps.name
, pf.name
, p.rows
, p.partition_number
, p.data_compression_desc
, fg.name AS filegroup_name
, fg.is_read_only
--, *
FROM sys.indexes AS ix
INNER JOIN sys.partition_schemes AS ps
ON ps.data_space_id = ix.data_space_id
INNER JOIN sys.partition_functions AS pf
ON ps.function_id = pf.function_id
INNER JOIN sys.partitions AS p
ON p.object_id = ix.object_id
AND p.index_id = ix.index_id
INNER JOIN sys.allocation_units AS au
ON au.container_id = p.hobt_id
AND au.type_desc = 'IN_ROW_DATA'
INNER JOIN sys.filegroups AS fg
ON fg.data_space_id = au.data_space_id
WHERE ix.object_id IN (OBJECT_ID('Sales.Orders_Partitioned'))
ORDER BY table_name
, ix.type
, ix.index_id
, p.partition_number;
--==========================================
-- Data in the READ_ONLY file groups is not there yet
--==========================================
SELECT * FROM Sales.Orders_Partitioned
WHERE OrderDate = '20130101'
--==========================================
-- RESTORE Filegroup Archive_pre_2014
-- We don't need to take the database offline, '
-- just restore the file
--==========================================
USE master
--RESTORE FILELISTONLY FROM DISK = 'WideWorldImporters_FILEGROUP_Archive_pre_2014.bak'
RESTORE DATABASE WideWorldImporters
FILEGROUP = 'Archive_pre_2014'
FROM DISK = 'WideWorldImporters_FILEGROUP_Archive_pre_2014.bak'
WITH RECOVERY
--==========================================
-- Data from 2013 is there
--==========================================
USE WideWorldImporters
SELECT *
FROM Sales.Orders_Partitioned
WHERE OrderDate = '20130101'
--==========================================
-- Other READ_ONLY filegroups can be restored at convenience
--==========================================

And that's how you can bring all your data to life while the database is online and the important parts of it can be accessed without having to wait for the rest to be available.
Conclusion
Partitioning is a very useful tool which in modern versions of SQL Server (2016 SP1 onwards) is even available in Standard Edition and should always be considered for large databases.
True that it will bring some extra complexity that needs to be addressed by the DBAs, but it's worth it and at least our customers can be sure we've got them covered.
I hope you learned something today or at least enjoyed reading this post, as always, feel free to comment in the section down below.
Thanks!
