
One of the technologies that surprised me when I heard of it was No-SQL databases.
As a database administrator that really distressed me at first; what is no-SQL? How can a database not be a relational database? Well, it’s been a few years, but finally my eyes opened and I’m ready to embrace No-SQL.

What is No-SQL?
Even the definition is not clear, you can find people that simply define it as non-relational databases where other people know it as not-only-SQL databases as they usually provide a SQL like language to access them. But at this point, the definition shouldn’t matter to us, let’s see a few concepts first.
How Can Databases Be Non-Relational?
Relational databases are based on the relational model most of us are very familiar with, and they are the result of a normalisation process defined on the '70s.
With the passing of the years and the increase of the amount of data to be processed, we have seen other database models (or design patterns) gaining importance in data warehouses and other big data projects. But the majority of them are still based in tables that are joined together, they produce the final data set.
The important piece here is something all databases have in common, including No-SQL databases, which is the ACID support (Atomicity, Consistency, Isolation and Durability), not how we model or store our data. As we’ll see later, the most used no-SQL engines are based on documents instead of tables and columns, but there are other types.
The data is therefore not normalised, which is the essence of relational databases and analysts [should] spend hours designing a model that can achieve the desired results.
In No-SQL database models, removing redundancies and creating the different relationships between tables is no longer a thing, same as strict schemas. Documents allow us to have flexible schemas and all the information we need to query at once should be in the document, as there are no JOINs between documents.
Types of No-SQL Data
As mentioned before, No-SQL database engines usually work on different types of non-relational data, but allow me to simplify them into two groups:
- Key-value pairs
- Documents
Key-value pairs would be the simplest representation of No-SQL. This post will be focused on data stored as documents.
Storing Data in Documents
I confess this didn’t sound right when I read about it, it looked like we were going from sophisticated relational database engines back to spreadsheets. I couldn’t be more wrong.
Allow me to explain myself, I was am a SQL Server DBA and my databases’ storage were structured this way:
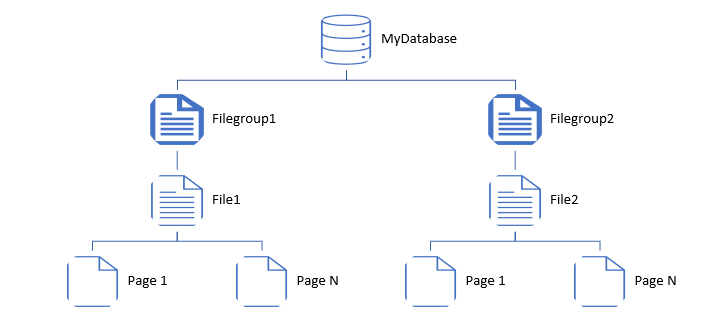
In SQL Server, there is one engine which is responsible for locating the data within the files and processing it when a query is submitted to the server.
This approach is fantastic and it works really well until the data grows to the point where the model can’t scale anymore. Bigger machines are no longer an option and considering the licensing costs, they might well be prohibitive.
No-SQL databases come to the rescue, and Microsoft Azure Cosmos DB claims unlimited throughput and storage. How is that possible? The reason is the different architecture, as No-SQL engines don’t scale up when your workload increases, they scale horizontally so you won’t hit limitations like when there is not a bigger processor or more memory that can be added to your SQL Server server.
The hierarchy of a Cosmos DB database would be as follows:
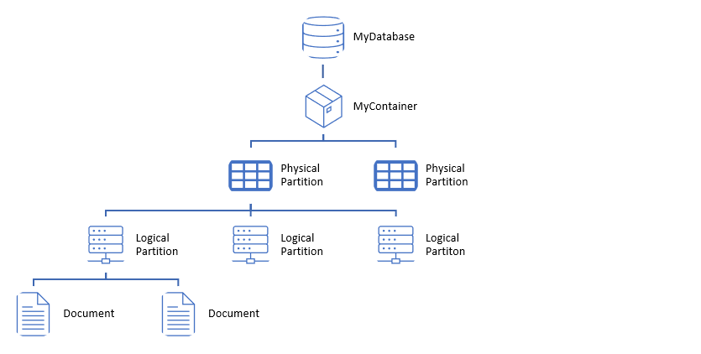
How to Scale Out
To be able to scale out, our data needs to be partitioned so it can be distributed in different containers (there are logical and physical partitions), as shown above.
The more throughput and storage we require, the more physical partitions are added to achieve it. There are storage limitations at the container level (at the moment of writing 20GB per logical partition and 50GB per physical), but there is no limit on the number of physical partitions per container.
Performance wise, there is also a limit at the physical container level, which is 10,000 RU/s (Request Units per second) but again there is no limit on the number of physical containers, hence that would be multiplied by n.
Partitioning
There is a word I have repeated a few times in the previous paragraph: partition. But why is this so important in Cosmos DB?
Upon creation each container will be defined by its partition key, and that can’t be changed after that, so we need to think carefully how we want to partition our data before even starting.
The documents we insert into our Cosmos DB database need to specify a partition key so they can be placed in the correct logical container.
How to choose the right partitioning key for your containers is a question that will end up with a well known answer - it depends. You need to know beforehand (or make a good polite guess) of how you will be inserting and querying your data to maximise the performance.
Globally Redundant
I mentioned earlier that licensing can be expensive when we need to keep adding cores to our servers, but also think about redundancy; it’s not only the hardware but also more licensing if you want to have readable copies of data.
Adding a redundant copy of your data is a one-click setting in Cosmos DB. You can have not only multiple read-only copies, but also read-write copies, which, if we have a globally distributed application, can make the difference between happy users and not so happy ones.
What is Next
In this post, I wanted you to start getting familiar with the concepts and maybe to try create your own Cosmos DB database, Microsoft has recently released a free tier (https://docs.microsoft.com/en-us/azure/cosmos-db/optimize-dev-test#azure-cosmos-db-free-tier), so there is no excuse why not to try it. And then you will be ready for the the following posts when I’ll get in on the action.
Hope you enjoyed the reading it and feel free to comment in the box below.
Thanks.
