
Whilst use of it is often dependant on your application and therefore unavoidable, sp_prepare can have a serious unintended impact on the performance of your queries.
Recently, I was looking into an interesting problem where a query was taking over 5 minutes when executed via the application, as opposed to a matter of seconds when ran with SSMS.
Running a trace showed us that the application was using sp_prepare and sp_execute to prepare and execute the statement which was generated by the application. So why was this causing such a large discrepancy from the “expected” execution time which we had observed when running the query ourselves?
We started by collecting the query plans in both cases and could see that when the query was executed from SSMS, the query optimizer had estimated a relatively low number of rows would be returned from the parameterised where clause. It therefore chose to carry out a seek on a non-clustered index, with a nested loop to get the selected columns from the clustered index.
In the case of the statement executed with sp_prepare and sp_execute, the plan showed that a hugely expensive scan of the clustered index was taking place. But with an identical value for the parameter, surely the plans should be identical?
Further investigation of the query plan showed that the estimated number of rows returned due to the where clause was spot on when the query was run directly, but wildly off when sp_prepare was used. To demonstrate this, I’ve crafted an example that you can follow along with.
Demo
In this demo, we are using the Stack Overflow 2010 sample database: https://downloads.brentozar.com/StackOverflow2010.7z
The code in full can be found in my github repo: https://github.com/JamesWMcCarthy/SQL-Demos/blob/main/sp_prepare_blog_demo.sql
We first create a non-clustered index on the Posts table, to recreate the problem:
CREATE NONCLUSTERED INDEX [IX_Posts_CommentCount] ON [dbo].[Posts] ([CommentCount] ASC); GO
Let’s start by clearing the plan cache, to ensure no existing plan is re-used. (Note: Do not do this on a production server!)
DBCC FREEPROCCACHE;
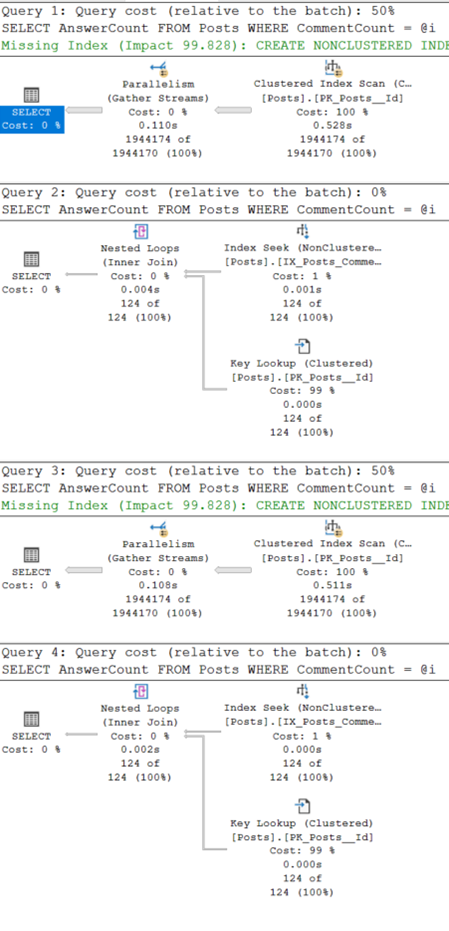
Now, let’s execute two queries, with the where clause values hardcoded:
SELECT AnswerCount FROM Posts WHERE CommentCount = 0; SELECT AnswerCount FROM Posts WHERE CommentCount = 27;
If we inspect the query plan used for each statement, we can see the optimizer chooses a different plan when the value is 0.
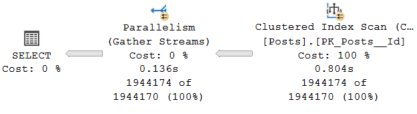
as opposed to when it is 27.
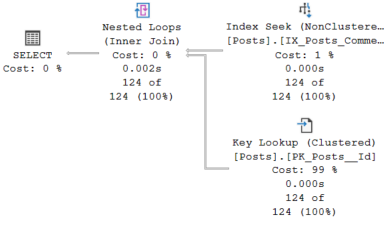
This is because 1.9M posts are returned where there are 0 comments, which is over half of the table, so a scan of the clustered index is more efficient in this scenario. In comparison, just 124 posts have 27 comments, so a seek of the non-clustered index combined with a key lookup is much more efficient.
Now let’s parameterise the query.
DECLARE @p1 INT; DECLARE @p2 INT; DECLARE @sql NVARCHAR(MAX) = N'SELECT AnswerCount FROM Posts WHERE CommentCount = @i'; EXEC sp_executesql @sql, N'@i INT', 0;
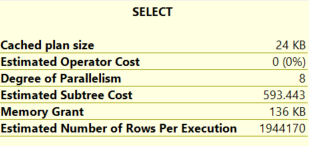
The parameter is sniffed, and the parallel plan is used. If we look at the row estimate, it is spot on:
Let’s clear the plan cache and do the same thing for the posts with 27 comments.
DBCC FREEPROCCACHE; EXEC sp_executesql @sql, N'@i INT', 27;
Again, a look at the query plan shows us that the parameter has been sniffed and the optimizer identifies the key lookup plan as the most efficient. But, what happens if we don’t clear the plan cache and run it again with @i = 0.
EXEC sp_executesql @sql, N'@i INT', 0;
In this case, the plan is reused, so the less efficient key lookup/nested loop combination is used when nearly 2M rows are being returned.
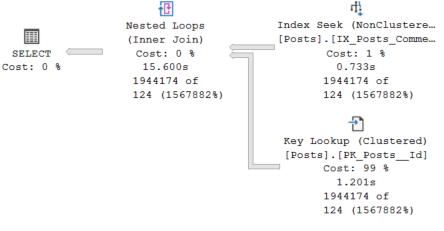
The estimate is still 124 rows, as the exact same plan is being reused.

This is a parameter sniffing problem, of which there are already plenty of resources on across the internet – but not the topic of this blog! Some of my favourite resources on parameter sniffing are:
https://www.erikdarlingdata.com/sql-server/defeating-parameter-sniffing-with-dynamic-sql/
Let’s now use sp_prepare and sp_execute instead of sp_executesql.
DBCC FREEPROCCACHE; EXEC sp_prepare @p1 OUTPUT, N'@i INT', @sql; EXEC sp_execute @p1, 0; EXEC sp_unprepare @p1; DBCC FREEPROCCACHE; EXEC sp_prepare @p2 OUTPUT, N'@i INT', @sql; EXEC sp_execute @p2, 27; EXEC sp_unprepare @p2;
A new plan is being used!

Furthermore, it is being used for both queries, irrespective of the value of the parameter. This might be expected behaviour if the plan was being reused, however we are clearing the plan cache between the two statements. Even stranger, the row estimate does not appear to be close to either of the number of rows we actually returned.
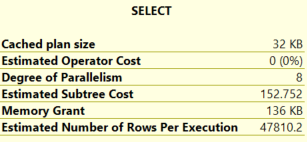
So what is causing this behaviour, and why is the estimate so wrong?
Let’s see what happens when we use the OPTIMIZE FOR UNKNOWN query hint. This instructs the query optimizer to ignore the initial values for the parameters, and instead use statistical data.
DECLARE @p INT; SET @p = 0; SELECT AnswerCount FROM Posts WHERE CommentCount = @p OPTION(OPTIMIZE FOR UNKNOWN); DBCC FREEPROCCACHE; SET @p = 27; SELECT AnswerCount FROM Posts WHERE CommentCount = @p OPTION(OPTIMIZE FOR UNKNOWN);
The query optimizer uses the same plan that it used when we executed the query with sp_prepare and sp_execute.
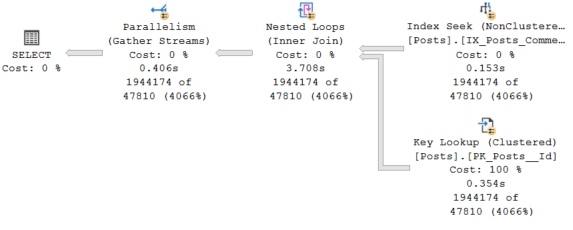
In addition, the estimates generated are also identical:
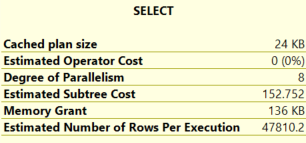
This illustrates that sp_prepare and sp_execute are using the density vector estimate, rather than looking at the values of the parameter passed.
If we dissect the statistics for the index we created, we can see the row estimate is being found by multiplying the number of rows in the table with the density of the CommentCount column.
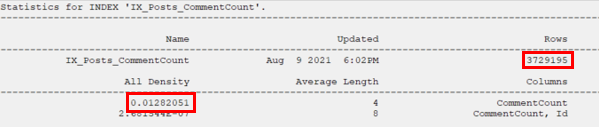
3729195 rows * 0.01282051 density vector = 47810.2 estimated rows.
How can we work around this?
In many cases, (including the particular real life problem I was looking at which motivated this blog post) the method of querying the database is a limitation of the application (in my case, queries were being issued with the JDBC driver). This means the simple answer isn’t just to stop using sp_prepare and sp_execute.
The first thing we could try is implementing a more appropriate index. You may have already noticed (or have been screaming at your monitor even!) that if we had just added AnswerCount as an included column to our index from earlier, then this query would have a covering index. This makes the “best” plan a lot less ambiguous, regardless of the parameters supplied.
We’ll give this a go now.
CREATE NONCLUSTERED INDEX [IX_Posts_CommentCount_INCL_AnswerCount] ON [dbo].[Posts] ( [CommentCount] ASC ) INCLUDE ( [AnswerCount] ); GO
And now run the query, using both executesql and prepare-execute.
DBCC FREEPROCCACHE DECLARE @p1 INT; DECLARE @p2 INT; DECLARE @sql NVARCHAR(MAX) = N'SELECT AnswerCount FROM Posts WHERE CommentCount = @i'; EXEC sp_executesql @sql, N'@i INT', 0; DBCC FREEPROCCACHE EXEC sp_executesql @sql, N'@i INT', 27; DBCC FREEPROCCACHE EXEC sp_prepare @p1 OUTPUT, N'@i INT', @sql; EXEC sp_execute @p1, 0; EXEC sp_unprepare @p1; DBCC FREEPROCCACHE EXEC sp_prepare @p2 OUTPUT, N'@i INT', @sql; EXEC sp_execute @p2, 27; EXEC sp_unprepare @p2;
These are all now using the indisputable best plan:
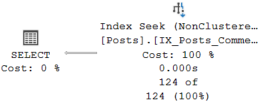
Of course, the usual caveats around indexing should be considered. Additional indexes improve select performance at the cost of inserts/updates, so the access patterns of the table should be considered. Furthermore, indexes require additional disk space, which also needs to be taken into account. We’d always recommend rigorous testing in a pre-production environment, as well as attaining performance benchmarks before and after the change to evaluate the impact of any new index.
Another thing we can do is wrap the query in a stored procedure. In some cases this may be appropriate, however it is worth noting that a change at the application level will likely be required in conjunction with this.
Let’s disable the index we just created so it can’t be used.
ALTER INDEX [IX_Posts_CommentCount_INCL_AnswerCount] ON [dbo].[Posts] DISABLE;
And then create a procedure to run the same query.
CREATE PROC [dbo].[sp_demo_proc] @i INT AS SELECT AnswerCount FROM Posts WHERE CommentCount = @i; GO
Now let’s see what happens when we run the procedure through simply executing it, or via sp_prepare and sp_execute
DBCC FREEPROCCACHE; EXEC sp_demo_proc @i = 0; DBCC FREEPROCCACHE; EXEC sp_demo_proc @i = 27; DECLARE @p1 INT; DECLARE @p2 INT; DECLARE @i INT = 0; DECLARE @sql NVARCHAR(MAX) = 'EXEC sp_demo_proc @i'; DBCC FREEPROCCACHE; EXEC sp_prepare @p1 OUTPUT, N'@i INT', @sql; EXEC sp_execute @p1, 0; EXEC sp_unprepare @p1; DBCC FREEPROCCACHE; EXEC sp_prepare @p2 OUTPUT, N'@i INT', @sql; EXEC sp_execute @p2, 27; EXEC sp_unprepare @p2;
The most optimal plan (with the indexes available) is used each time.
As we’ve demonstrated with this demo, using sp_prepare leads to poor row estimates which are calculated based on the density of the data. In some circumstances, this can have a huge impact on the performance of a query due to inefficient query plans. We’ve shown a couple of potential ways this can be worked around
Finally, a slight aside:
You may have wondered why I laboriously wrote out sp_prepare and sp_execute as individual T-SQL lines each time, when Microsoft appeared to have created sp_prepexec exactly for me to use to condense this blog!
The official documentation (https://docs.microsoft.com/en-us/sql/relational-databases/system-stored-procedures/sp-prepexec-transact-sql?view=sql-server-ver15) simply states: sp_prepexec combines the functions of sp_prepare and sp_execute.
However, in my experience creating and testing this demo, it looks like queries run using sp_prepexec from SSMS can be treated as ad hoc, rather than being prepared as a parameterized query.
Further investigation on my part is necessary to get a definitive answer on this, which may end up as an amendment to this blog post at a later date, or as a sequel if it turns out to be interesting enough to merit it!