This post is the first in a series of 2 posts related to transactional replication. In this post I’ll discuss some of the internals of transactional replication in order to better understand where its bottlenecks are before going on to discuss some general performance tips. In the subsequent post I discuss how to marry distributed partitioned views with transactional replication in order to achieve performance gains of several orders of magnitude. I assume a familiarity with the basics of replication and, in particular, the publisher model that is often used to describe replication.
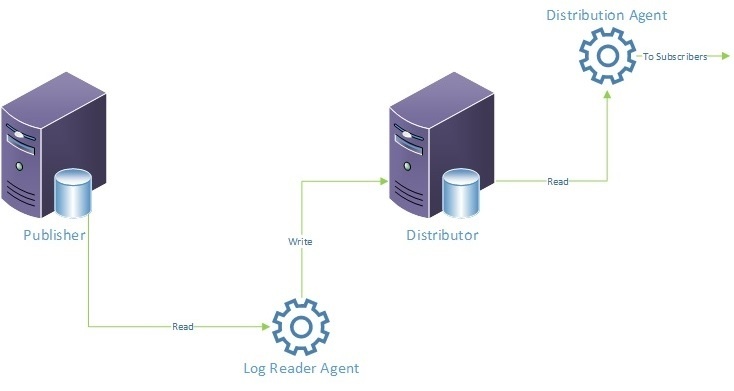
In the image below we can see the basic components involved in transactional replication. The log reader agent (which is located on the distributor) has two threads, the first of which is responsible for reading the transaction log of the published database. The second thread of the log reader agent is responsible for writing replicated commands to the MSrepl_transactions and MSrepl_commands tables in the distribution agent.
In the context of replication a transaction is synonymous with a database transaction. For example, the following update statement could be considered a transaction:
update products
set price = 2.00
where product_type = 'Widget'
If the above update statement updates 1000 rows, the commands (in the context of transactional replication) represent each command needed to update each individual row in the products table.
There are a few important features of the log reader agent that I would like to draw attention to.
The above points highlight how performance of the log reader can be impacted. For example, take a transaction that updates a large number of rows (say hundreds of millions) and let’s imagine that this transaction takes 4 hours to complete. During those 4 hours the log reader is doing nothing other than waiting for that 4-hour long transaction to complete (this is due to point 3 above). However, on the publisher, other transactions are still happening concurrently. So when the large transaction completes, not only does the log reader need to read and process that transaction but it also has 4 hours’ worth of other transactions to read after it has dealt with the large transaction.
Regarding the writer thread of the log reader, one important thing to note is that for every row that is updated on a published table, a row is inserted into the MSrepl_commands table. So if one hundred million rows have been updated at the publisher, this will result in that many rows being inserted into MSrepl_commands.
The Distribution Agent uses the stored procedure sp_MSget_repl_commands, which identifies the transactions and commands it needs to replicate from the MSrepl_commands and MSrepl_transactions tables on the distribution table. These commands are then subsequently applied at the subscribers.
It is important to note that, when delivering data to subscribers, a single transaction at the publisher that updates 100 million rows in one statement, will result in 100 million updates, which each update 1 row.
We can clearly see then that larger updates will have a direct impact on the size of the distribution database, as well as the efficiency of the distribution agent which reads from these tables and then issues these commands to be written (individually) at the subscribers.
In essence transactional replication is quite a straight forward technology that involves very few moving parts and can be summarised in the following steps:
Whilst the above summary is, in reality, an over-simplification it does nicely illustrate the basic processes and it does show why replication is not very well suited to updating large sets of data.
One of the most obvious impacts of transactional replication is the impact of the reader thread that the log reader agent has on the log file of the published database. The log file is predominantly written to, which results in a consistent pattern of sequential writes on the log disk. However, the introduction of the log reader agent immediately doubles the workload on the log file of the published database (i.e. for every transaction that is written, the log reader needs to now read that transaction too). Additionally the pattern of IO activity becomes more random than sequential in nature.
Below is a list of general performance improvement tips for transactional replication that I further expand on later.
Some of the above tips provide obvious benefits but I’d like to expand a little bit on a few of the above tips.
Replicating stored procedures is a very effective means of overcoming the limitation that is faced when updating a large number of rows. By replicating a stored procedure instead of the underlying table(s), rather than the updated data being replicated it is only the execution of the stored procedure that is replicated to the subscriber. Whilst the same number of rows would be updated at the subscriber, we avoid having to move these commands through the log reader to the distribution database and on to the subscribers. Using the example of the 4-hour transaction described above, whilst the transaction would still take 4 hours to complete at the subscriber (all things being equal) the log reader would be free to process all other ongoing transactions on the log reader.
The ability to replicate stored procedures can significantly improve performance so it should be given consideration where updating a large number of rows is a requirement.
Note that this benefit is lost if a transaction isolation level of read uncommitted is used. When this level is used, all updates are processed as separate commands instead of a single procedure call.
Using Read Committed Snapshot Isolation at the subscribers can also offer significant performance improvements. Ordinarily the reason data is replicated is to offload search or reporting functionality onto subscribers. Under this scenario it is quite common for report users to block incoming replicated transactions, which will result in a perceived loss in distribution performance. By using RCSI we can prevent readers from blocking writers.
With regards to agent profiles, CommitBatchSize and CommitBatchThreshold on the distribution agent can be increased, which does improve the performance of large updates/inserts/deletes. However this would ordinarily result in increased duration of blocking on the subscribers. That said, if RCSI is implemented on the subscriber then this can offset the negative impact of blocking. Increasing these values two to ten-fold can give 10-30% improvement on insert/update/delete statements on the subscriber (https://technet.microsoft.com/library/Cc966539). Note however that this is old advice that applied to SQL Server 2000.
The MaxCmdInTrans option on the log reader agent profile is an option that is often mentioned with regards to large transactions. However, due to the potential loss of transactional consistency I wouldn't ordinarily recommend this option without having explored other possibilities first.
{kind=link}