Everyone is talking about Big Data. What it is, how important it is and why it should be part of your strategy or roadmap. But what does it really mean? I can only talk from my experiences with various customers and what it means for them. For some it means large volumes of difficult to use data: weblogs, social media streams or XML documents, perhaps all in different formats or from different suppliers. Whilst the business is desperate to extract customer insight, understand brand perception or see how location affects sales, the BI team are struggling to make use or sense of this voluminous, complex data. For many other customers it simply means a traditional data warehouse that has just got too big!
Currently people are attempting to tackle big data in two ways. Firstly a lot of businesses are starting to adjust the way they deliver their BI projects to be more agile. Business users were complaining that the BI system was slow and any enhancement requests were put on a huge backlog that, by the time it got delivered, the need had passed. So BI teams are adopting agile methodologies such as Kanban not only to deliver value more regularly but to tie those deliveries back to clear business need. Secondly businesses are dabbling into the open source world of Hadoop, HDFS, MapReduce etc. Often it leads to leaning on traditional development to hand craft bespoke components to extract any value from the data. In my opinion this is giving people a taste of the possible with big data but it is proving immensely difficult in terms of the skills needed to deliver something production ready. I liken it to writing a Shakespeare size play full of code that only a few people really grasp but everyone thinks is cool. If you have a theatre full of advanced developers and can cope with the risk of using bespoke code and open source components then this is a an option.
For those of us with a simpler desires then welcome to the Microsoft Parallel Datawarehouse (PDW). Microsoft’s premium data warehousing appliance. It is eminently scalable and performance is literally off the chart.
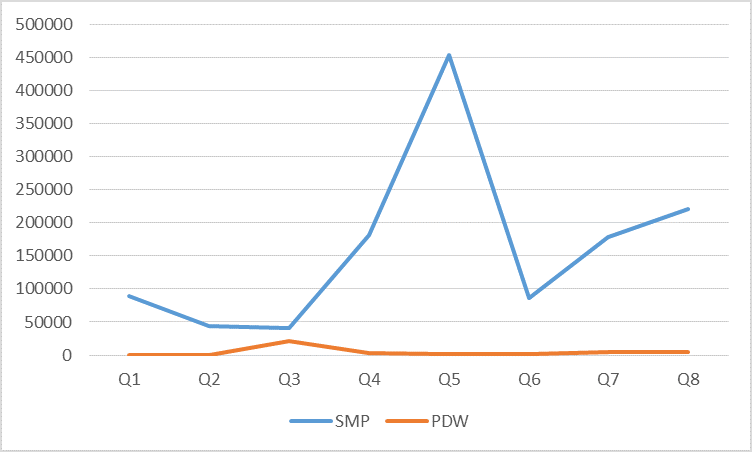
Figure 1 – PDW versus SMP SQL across 8 real life customer DWH queries
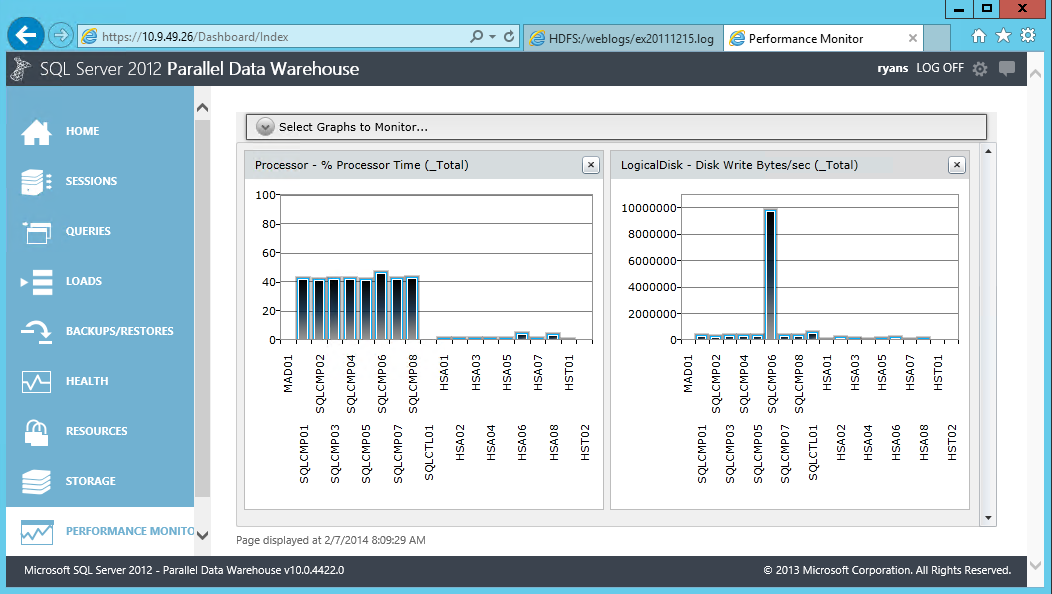
Figure 2 – PDW Performance Dashboard highlighting all SQL nodes being used to run a query
The PDW offers the ability to spread data across multiple instances of SQL Server 2012. PDW offers blistering performance, the ability to rethink how you model data and gives you the tools to make your current datawarehouse techniques more efficient. The appliance is easy to use with the complexity of parallelism abstracted by the familiar SQL Server. Using the existing MS BI stack you can migrate your existing warehouse quickly and deliver a scalable platform that can grow up to 7 racks full of power Dell or HP hardware. Support is within a 4 hour window and can be direct through the hardware provider or Microsoft directly.
The piece de resistance, however, is the ability to co-host a Hadoop cluster in the PDW appliance. Thus you can store and query your unstructured data alongside to your traditional datawarehouse. As well as that by using Microsoft’s Polybase technology you will be able to build T-SQL queries to join up your structured and unstructured data. The great thing here is Microsoft has hidden all the complexity of adding data and building queries across it so all you need to do is go grab all the invaluable big data sources you have, load them onto your PDW appliance and bob’s your uncle and customer insight is your aunt!
{kind=link}
{kind=link}