The aim of this article is to provide a high-level overview of Extract, Transform and Load processes in Azure. Throughout the post, I will share my own experience working with Azure Data Factory and Automation over the last few months, and this blog will act as a primer for future posts, where I will focus in depth on Azure Automation and demonstrate how to author Automation Runbooks to manage Azure / SQL Server resources.
I’m constantly looking for new insights, so if you have any thoughts or experiences working with Data Factory, Automation or other Azure components please share them in the comment section.
Azure ETL – Challenge or Opportunity?
Customers working in Azure are most likely to be a) shocked, b) confused or c) relieved when faced with the issue of implementing ETL. For some, Azure is an enabling platform for performing data operations of unprecedented scale and complexity. For others, integration of on-premises and cloud data and running ETL in the cloud can be a massive challenge and a steep learning curve. The importance of diligence and planning when considering paths to Azure cannot be overstated and should be addressed with a focused approach, proof-of-concepts and expert support.
Take something as trivial as scheduling, for instance. Seasoned on-premises ETL practitioners armed with SQL Agent jobs and master packages will be shocked to learn that there is no direct migration path for SSIS packages and no SQL Agent service in Azure. There are other tools in Azure to handle automation and scheduling, but none have the ability to call a SSIS package (at least not directly). This lack of Azure SSIS means businesses whose information infrastructure depends on SSIS have to develop a new approach using the tools available in the cloud.
ETL Criteria
With the emergence of new data sources such as streams, APIs and web/cloud services, Azure ETL needs to support a new model of data integration. Unlike the on-premises ETL model, where data is typically processed in SSIS and then loaded to a target data store such as a Database, Warehouse or File, the Azure model for ETL would require the ability to support a broad range of sources that continuously emit data.
This new model has been described by some as “Acquire, Process & Publish", or AP2. The fundamental differences in how data is produced and consumed, combined with the requirement for tight integration with Azure Services’ components, indicate that the concept traditionally known as “ETL” takes on a different form in the cloud. Of course, it would be ludicrous to think that ”ETL is out, AP2 is in” but, as Azure and cloud technologies mature we may be (and should be) going through a paradigm shift in how ETL is approached.
From a functional perspective, regardless of tools or data, any ETL process aims to fulfil the following core requirements:
• Integration (range/nature of sources and destinations, work with different types of data)
• Ability to perform and reuse complex transformations
• Workflow engine (execution logic)
• Job scheduling and automation
For a comprehensive list of ETL tool criteria, I suggest you look at Jamie Thompson's blog on cloud ETL, which was first posted in December 2013. Obviously, cloud- and business-specific factors will create unique requirements for ETL, but these will generally fall into the above categories.
For customers with the Microsoft platform, a lack of options for running SSIS directly from Azure means they are left with the following choice:
1) ETL process redevelopment (new tools)
2) SSIS process redevelopment (new ETL infrastructure / on demand)
3) Hybrid solutions
The recent release of the SSIS Feature Pack for Azure seemed to indicate that SSIS is still part of Microsoft’s plans for Azure. While it’s encouraging to see SSIS extended to work with Azure services, I have seen very little evidence so far of Azure extending to accommodate existing SSIS work, and worry that this trend might continue. It’s hard to tell what SSIS/Azure ETL architectures we will see established over the next few years, so I will try and explain the options available to customers at this time.
Azure Data Factory
The functionality and tools available in Azure is constantly changing. In the last 18 months, Microsoft have released Azure Automation and Azure Data Factory, and despite the latter remaining in public preview, these two tools are establishing themselves as tools of choice for data integration / ETL in Azure.
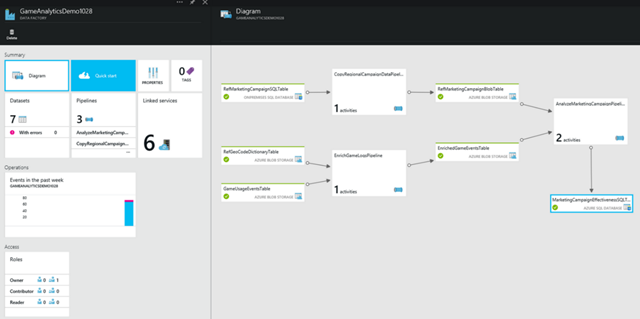
Azure Data Factory (ADF) is a fully managed service/platform for developing data pipelines. ADF can integrate various cloud and on-premises data stores and perform complex transformations at scale using C#, Pig, Hive and MapReduce (with HDInsight). The screenshot below shows a sample Data Factory that enriches game log data held in BLOB storage with marketing data from an on-premises database and outputs data for campaign analysis to an Azure SQL Database:
Azure Data Factory was designed as a service for batch processing of data and is very different from SSIS, but is probably easier to describe when juxtaposed with Microsoft’s on-premises ETL tool.
To show how ADF works I will build a sample ADF called POC-AzureDataFactory, which will connect to my local SQL Server and move 2m rows of data to an Azure SQL Database.
Prerequisites
Before starting, I prepared dbo.LocalData in my local SQL Server TestDatabase as well as dbo.AzureData in a vanilla AdventureWorksLTV12 Azure database. I then used a trial version of Redgate’s Data Generator tool to feed 2m rows of test data into dbo.LocalData:
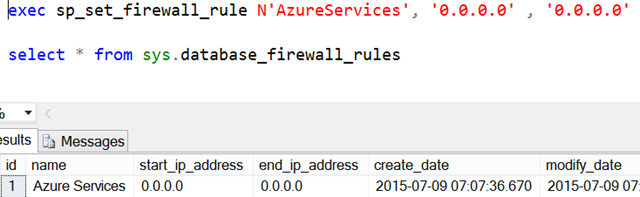
On the Azure side, I had to ensure that the firewall is configured to accept inbound connections. Azure SQL DB firewall has two levels of configuration: server- and database-level. Typically Azure SQL Servers accept connections from Azure Services, but if not, this option can be configured using the Azure portal, the New-AzureSQLDatabaseServerFirewallRule PowerShell command, or executing sp_set_firewall_rule against master within Azure DB.
Once the server-level permission for Azure Data Factory is granted, database-level restrictions have to be lifted as well.
Azure Services are not able to connect to Azure databases by default, so you can apply and verify the fix by running the following query against Azure SQL DB (NOT master):
Microsoft Data Management Gateway
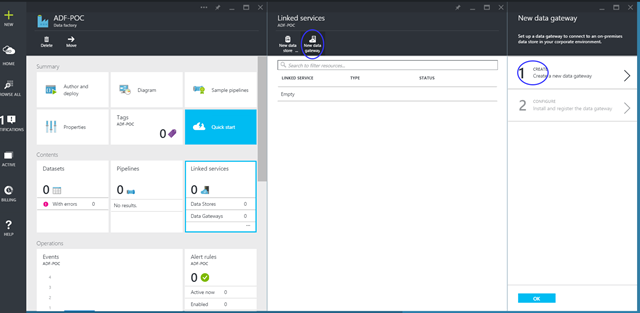
Now that we’ve allowed ADF to work with our Azure DB, we will create a Data Factory named POC-AzureDataFactory. Before the ADF service can work with our local SQL Server we need to download, install and configure the Microsoft Data Management Gateway. Once installed, the gateway should be configured using a key that can be obtained from the Azure Portal:
A single Gateway can be used for multiple data sources on-premises, but is tied to a particular Data Factory and cannot be shared with other Data Factories. For more info on the Data Management Gateway, check Azure documentation.
Once our gateway has been registered and the service is running on-premises, it should appear as “Online” in the “Linked Services” section of the Portal. We are now ready to create our linked services. Azure Data Factories can be developed and managed through PowerShell, however that is mostly useful when used in combination with Automation or other Azure IaaS components. For the purpose of this example, go to “Author and Deploy” to use the in-built JSON scipting interface.
Azure Data Factory Linked Services
First, we need to create the linked service for our on-premises SQL Server. Selecting “New data store” and “SQL Server” opens up a JSON template for OnPremisesSqlLinkedService. Scripting the on-premises SQL Server linked service is fairly straightforward. The JSON templates have in-built syntax checking so a typical missing property error can usually be fixed by correcting a misplaced comma or bracket. Be mindful, however, that this offers little protection against errors within strings and properties.
In my LocalSQLServer linked service I did not need to use any special characters, but its important to remember to escape any special characters you may have in your JSON definition. Another useful thing to remember is to escape special characters- when scripting user names or connection strings in JSON, use the following guideline for backslashes:
Standard: MYSERVERUSER --> JSON: MYSERVER\USER
Standard: ‘\’ --> JSON: ‘\\’
It’s important to ensure that connection strings are valid and you pay special attention to semicolons, parentheses and backslashes. After checking my connection string, I provided my local user name and password in the properties outside. If you require SQL Server Authentication you will need to adjust the connection string, ensure that the login specified has the required permissions, and remove username and password properties from the linked service JSON (Note: I recommend source controlling your JSON code in an external editor). After that we deploy our LocalSQLServer linked service, and after it provisioned successfully it should display as “Online” in the Linked Services blade of the Data Factory.
Any attempts to delete resources that other components depend on will be detected by the JSON editor and will have to be mitigated by keeping copies of the JSON scripts (another argument for external source controlling your JSON), and deleting / redeploying each component in sequence.
After deploying our LocalSQLServer on-premises linked service, we will need to create the table structure or dataset that our SQL Server data will be sourced from in the ADF JSON editor:
The important thing here is to use correct column names and ensuring the right table name and associated linked service are specified. The data type property in the structure should only be used for reference. The data type property is mandatory in the JSON definition, but SqlSource and AzureTableSink ignore these and inherit data types from underlying tables, handling any implicit conversions.
Once we define the local dataset and check for any errors we can deploy the dataset and move on to defining our resources on the Azure side.
To create the Azure DB linked service, we have two options: “New data store” -> “Azure SQL” from the “author and deploy” blade, or we could create the Azure SQL DB linked service from the “Linked Services” blade in the data factory.
Scripting the Azure Linked Service is fairly straightforward, the only things to be mindful of is that the linked service is of the type AzureSQLLinkedService and that the connection string is valid and uses the right credentials.
Unfortunately, unlike our LocalSQLServer linked service, the “Linked Services” blade doesn’t indicate whether our AzureSQLServer linked service connected successfully. It would be useful if we saw functionality for performing basic connectivity tests added in future updates.
Now that we have our linked services and datasets defined, we will use the JSON editor to define our pipeline. It can be seen to this point that linked services and datasets represent the ADF equivalents of SSIS sources and destinations. But what about complex transformations? SSIS is known to handle complex transformations well, so how do ADF activities compare? Unfortunately, the breadth of choice for connectivity is accompanied by limited options for activities and transforms. At the time of writing, the only activities available in ADF are Copy, Hive, Pig, AzureML batch score, and SPROC. Custom .NET activities are also supported, but in limited capacity. This is likely to continue as long as the tool stays in private preview. For more detail on using .NET tasks in ADF, I suggest you read the Azure documentation on custom activities in ADF.
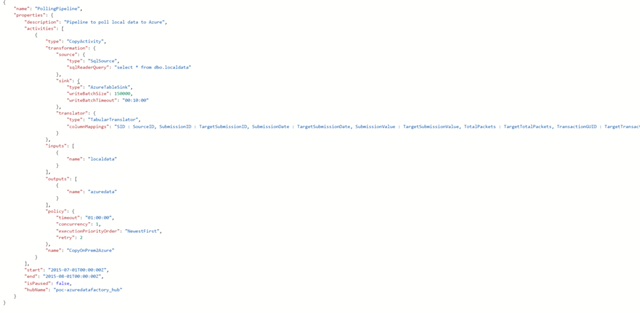
After defining our data stores and structures, we can define the pipeline to be used in our POC-AzureDataFactory. We can do this by accessing the “Author and Deploy” blade and selecting “New Pipeline”. The activity I used in my data factory was a simple copy activity. Clicking “Add Activity” -> “Copy Activity” generates template JSON which can be amended to meet the requirements of your pipeline. The below screenshot shows the JSON configuration I used for my PollingPipeline:
There are a couple of important aspects to the pipeline definition: the copy activity JSON must define the transformation correctly. Azure Data Factory offers limited tools for troubleshooting and logging of pipelines, so I suggest incrementally testing your pipeline and dataset scripts.
The pipeline consists of 3 important elements:
1) Source – in my case I used SQLSource
2) Sink – in my case AzureTableSink, other sinks include blob, Azure queue, document db collection, Oracle as well as SQL sink. Note:*** My attempts at configuring a SQL Sink were unsuccessful, and I’m not sure how functional the other sink types are.
3) Transformation – typically an input/output and transform logic
When creating pipelines in ADF, special attention must be paid to values provided in the JSON definition. In the case of our local SQL to Azure DB copy activity, our inputs and outputs are the LocalData and AzureData datasets we defined earlier. I would recommend that special attention is paid to the sink and transformation property definitions.
As can be seen from my screenshot before, the AzureTableSink type requires two additional parameters, WriteBatchSize and WriteBatchTimeout. We can configure these to ensure our pipeline meets our requirements.
Once our inputs, outputs, source and sink have been configured, we can define our transformation logic in the JSON editor. Our activity is a straightforward copy from a local SQL Server, but for the purpose of this exercise, the SID column of our LocalDataset has to map to a SourceID column in our Azure SQL DB. This mapping can be achieved by defining a translator property alongside our source and sink definitions. The translator must be of the type TabularTranslator and the required mapping should be defined in the ColumnMappings property using the following syntax:
“ColumnMappings”:”SrcCol1 : TgtCol1, SrcCol2 : TgtCol2, SrcColn : TgtColn”
The one thing to note here is that I found that the pipeline wouldn’t work if the column names of my local and azure tables would match, hence I attached the ‘Target-‘ prefix to my target column names.
The last element of our pipeline script is to configure the policy for our CopyActivity as well as the properties of our Pipeline. “Start” and “End” denote the timeframe within the pipeline exists. The “IsPaused” flag can be used to temporarily pause our pipeline from performing any activities, and the hubname property would be useful if we had multiple pipelines within our Data Factory and wanted to logically segregate our different resources into distinct data hubs. A data hub is the ADF term for a combination of Data Store and Compute Linked Services.
Once all elements of my POC-AzureDataFactory have been defined and deployed, I can monitor the execution status of my ADF by going to the Diagram blade and checking the status of the output dataset. Upon successful execution I can check that my target table was populated with the data:
One thing I would like to note is that It was a struggle to get ADF to perform my job against an Azure SQL DB on B and S0 plans. When I ran the test against P1 or P2 Azure databases, the tests ran successfully (and pretty fast). With a P2 target, I was able to complete my transfer of 2 million records in under 6 minutes, whereas the job would typically fail on S0 and B. I think the reason my tests were failing on B and S0 databases was a suboptimal configuration of job timeouts and write batch size. I’m pretty sure I could have achieved a faster time using a different configuration for my Azure linked service and dataset, but that’s for another post.
The thing that stood out for me when working with ADF was the development experience. In SSIS, I had gotten used to the SSIS Control Flow / Data Flow paradigm and the flexibility of being able to utilise both SSIS transformations and free hand T-SQL. It’s important to note here that ADF “transformations” like those we’re used to having in SSIS (the ADF equivalent is an “activity”) do not exist and have to be manually developed in .NET & JSON. ADF does have a GUI of its own, and while it can be useful when visualising the chain of activities within a data pipeline, with all elements of a Data Factory existing as scripts, it does little in helping the user configure the steps required in getting data from one state to another.
The development experience is not optimised for business users. The ADF GUI visualizes chains of activities to control logic and simplifies development, but not by much. In some organizations I work with, where responsibility for ETL lies with BI teams, I see this as a massive barrier to adoption. In a world where multidimensional models get abandoned or heavily underutilised due to the perceived complexity of using MDX, I see these development and skills requirements being a large deterrent for businesses. Don’t get me wrong, I’m not demanding an SSIS-style “drag-drop-configure GUI”; I just don’t believe that .NET development & JSON scripting should be a minimum requirement for moving and transforming data in the cloud. I’m hopeful of seeing improvements in this area, either through abstracting some of the JSON code or through providing a script-generation tool. Since integration with SSIS is currently lacking, many problems could be solved by having an SSIS linked service (to work with SSIS assets) or alternatively having an SSIS activity within ADF to integrate existing packages. Time will tell.
Additionally, a rethink may be required around scheduling of jobs. The ADF mechanism for scheduling is robust, but uses an approach different to traditional scheduling. Instead of configuring a schedule for executions, ADF scheduling works by configuring the availability of the datasets within a pipeline as well as the availability of the pipeline itself. For more information on scheduling and executing Azure Data Factories, see Cem Demircioglu's video on Slices and other ADF scheduling concepts. To those interested in ADF, I highly recommend you check out Cem’s other videos as well.
When ADF first went into public preview, the only data stores available were Azure blobs, on-premises and Azure SQL databases. Today, the available list of data sources has been extended to include File Systems, Oracle and DB2, PostgreSQL, Teradata, Sybase and MySQL. These extensions seem to suggest that Microsoft have committed to ADF as the Azure Data Integration / ETL tool of choice, but the feature set for a general release has not been decided. This means that customers with specific requirements (e.g. FTP over SSH) will have to resort to deploying micro-VMs with SSIS to support existing processes. I would consider that design suboptimal in a cloud environment, and think that this is an area that requires some short-term, if not immediate focus from Microsoft. Whilst they have done a good job of providing for the breadth of modern data sources and new data generation/consumption methods, they are yet to provide a simple answer to the question that 80% of customers moving to Azure will have: “How do I move my ETL workloads to Azure?”
Organizations for whom ADF enables the necessary scale, reliability or data integration, will not mind the development required or the cost and complexity of the development effort. For others, such as SMEs exploring their cloud options, the steep learning curve and high adoption cost will continue to remain a major deterrent to utilising Azure. On the bright side, new Azure functionality is being released at an encouraging rate. Admittedly, it’s hard to forecast what the platform will look like in 12 months’ time, but my hope is that Azure will reach the stage where traditional ETL workloads (SSIS) have an organic migration path into the cloud. I think most organisations are not ready to make full use of ADF yet and will continue to use traditional tools for their day-to-day ETL requirements, and look to Azure Data Factory as the tool for super-scale data jobs in resource contention scenarios.
In summary, ADF will delight organisations with hybrid deployments and requirements for massive scale data jobs. ADF will benefit customers with unique infrastructure challenges, but at the same time it will frustrate customers looking for a way to replicate SSIS functionality “as-is” in Azure. Utilising Azure Data Factory in combination with Azure PowerShell gives organisations administration and execution logic control over large-scale data operations from a single pane of glass, but is a different type of service from SSIS. Simply put, ADF is not meant to replace SSIS and data ingestion is not a substitute for old-school ETL solutions (yet).
Azure Automation
Azure Automation, a service available since early 2014, is a direct descendant of Services Management Automation introduced with System Centre 2012. From the Microsoft documentation on SMA, it can be seen that the two tools share an identical runbook format and are underpinned by the same Workflow engine (Workflow Foundation). Since SMA can be extended to the public cloud with the use of System Centre, it would not be far-fetched to say that Azure Automation is effectively a public cloud flavour of SMA. The Azure Automation service entitles users to 500 free minutes of Automation per month, after which Automation charges on a pay-as-you-go model, charging one-fifth of a cent per minute of automation job.
Azure Automation works by authenticating to an Azure subscription or management certificate. This authentication enables Automation to execute and monitor PowerShell Workflow scripts across Azure services without the need for an Automation host. In the context of cloud BI or PaaS/IaaS, it means that Azure Automation blurs the line between Service Administration and ETL. The reason why Azure Automation should be considered part of a discussion on Azure ETL is because of its ability to integrate data elements across separate Azure services.
Let’s say you wanted to automatically shrink your VMs or spin down elements of your infrastructure outside of business hours. Azure Automation would be able to fulfil this requirement by bringing PS Workflow, Scheduling and Azure PowerShell together in the same integrated development environment (IDE). This gives an unprecedented amount of control and flexibility over Azure resources as well as the ability to distribute and reuse data elements of Azure Services throughout the entire platform.
For me this is the coolest aspect of Azure Automation: the ability to manage cross-platform resources from a common IDE and logically isolate (and reuse) resources required for a task, without the need for configuration tables, flat files or variables stored in blobs. Using Automation Accounts; configurations, variables and other resources are stored globally as PowerShell objects that are accessible from within Automation Runbooks and Azure PowerShell. This means that all jobs running under the Automation Account can read /write connection strings, logins, certificates, schedules, string and numeric variables from/to a globally available collection of objects.
The Automation mantra reads: “If you plan to do it more than once, do it in Automation”. While I would advise against taking that literally (some jobs are complex/impossible in PS Workflow, and will require another IDE), it is good guidance to go by. Azure Automation scripts and Automation assets can be easily authored, tested, deployed and scheduled. The current Automation Scheduler has a major limitation in that 1 hour is the smallest unit of time, but I don’t see this remaining the case in the future.
The Microsoft Script Centre contains a gallery of sample runbooks submitted by the Automation team and the community. It constantly gets updated with new scripts, so I suggest you check it out for inspiration on Automation. We will build and cover some runbook examples ourselves in later posts, but for now it’s useful to show a basic script to discuss Automation’s capabilities:
workflow Use-SqlCommandSample
{
param(
[parameter(Mandatory=$True)]
[string] $SqlServer,
[parameter(Mandatory=$False)]
[int] $SqlServerPort = 1433,
[parameter(Mandatory=$True)]
[string] $Database,
[parameter(Mandatory=$True)]
[string] $Table,
[parameter(Mandatory=$True)]
[PSCredential] $SqlCredential
)
# Get the username and password from the SQL Credential
$SqlUsername = $SqlCredential.UserName
$SqlPass = $SqlCredential.GetNetworkCredential().Password
inlinescript {
# Define the connection to the SQL Database
$Conn = New-Object System.Data.SqlClient.SqlConnection("Server=tcp:$using:SqlServer,$using:SqlServerPort;Database=$using:Database;User ID=$using:SqlUsername;Password=$using:SqlPass;Trusted_Connection=False;Encrypt=True;Connection Timeout=30;")
# Open the SQL connection
$Conn.Open()
# Define the SQL command to run. In this case we are getting the number of rows in the table
$Cmd=new-object system.Data.SqlClient.SqlCommand("SELECT COUNT(*) from dbo.$using:Table", $Conn)
$Cmd.CommandTimeout=120
# Execute the SQL command
$Ds=New-Object system.Data.DataSet
$Da=New-Object system.Data.SqlClient.SqlDataAdapter($Cmd)
[void]$Da.fill($Ds)
# Output the count
$Ds.Tables.Column1
# Close the SQL connection
$Conn.Close()
}
}
The script above does a good job of demonstrating how Azure Automation works. PowerShell Workflow adds the ability to program execution logic (ForEach loops, Sequence, Checkpoints) and allows setting up parameters, which can be fed to our PowerShell workflows. I see many organizations’ DBMS implement similar functionality using workarounds like custom stored procedures and config tables, but that often leads to increased management and maintenance costs and fills their SQL Servers with performance-eroding logic.
The reason why I wanted to talk generally about ETL in Azure before deep diving into Azure Automation was to give some indication about why Azure Automation would even be considered for an ETL process in the first place. If the necessary processing and transformation can be handled in the SQL Server database engine, Azure Automation can prove to be a useful tool in integrating SQL Server and Azure SQL Database with the wider infrastructure or platform. I think that Azure is still a good 18-24 months away from reaching mature functionality. In the meantime, I expect that Azure Automation will feature as a tool for creating short-term workarounds to support existing ETL processes.
As previously mentioned, Azure tools open up a whole range of new techniques for data extraction and transfer. Due to limited resources and other priorities, it’s quite likely that we will first see Azure “broaden” its reach, rather than addressing existing integration issues and gotchas.
My favourite thing about Azure is that despite not being as mature as Microsoft’s on-premises platform, it encourages businesses to get creative with data and produce information that was previously out-of-reach. As a data professional I recognise that Azure’s ongoing evolution might increase the risk perceived by potential customers, however it’s encouraging to see that the platform is evolving in the right direction.
In the next post, I will take a closer look at Automation Assets as well as developing some more advanced runbooks using Azure Automation. Over the next few weeks, I will be doing my MCSE certification and cooking up the tests for future publications, so make sure you watch this space!
To understand more about how Coeo can help you with Azure deployments, please
Additional Resources:
Introduction to ADF:
https://azure.microsoft.com/en-gb/documentation/articles/data-factory-introduction/
https://azure.microsoft.com/en-gb/documentation/articles/data-factory-faq/
http://blogs.msdn.com/b/bluewatersql/archive/2015/01/26/hello-azure-data-factory.aspx
https://azure.microsoft.com/en-gb/documentation/articles/data-factory-copy-activity-advanced/
ADF Concept Demos:
https://azure.microsoft.com/en-gb/documentation/articles/data-factory-tutorial/
Get started with Azure Automation:
Azure SQL DB Connectivity Troubleshooting Guide
http://social.technet.microsoft.com/wiki/contents/articles/1719.aspx
Don't miss out - sign up to recieve the latest technical articles, exclusive event invitations and more:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}